Textdarstellung
Einführung
Da ein Computer alle Inhalte lediglich mit Zahlen darstellen kann, ist es nötig, eine Zuordnung zwischen Zahlen und Zeichen herzustellen.
Die gängigsten Verfahren arbeiten hier mit einer Codierung auf Zeichenbasis, so dass einzelnen Zeichen eine individuelle Codierung zugeordnet wird. Solche Zuordnungstabellen nennt man auch Zeichensatztabelle oder C Codepage.
Andere Codierungsarten ordnen beispielsweise nicht einem einzelnes Zeichen, sondern ganzen Zeichenkombinationen, Wörtern und Sätzen einen Eintrag in einer Zuordnungstabelle zu. Ein solches sogenanntes Wörterbuchverfahren ist beispielsweise das weiter unten vorgestellte LZW-Verfahren.
Die wohl bekannteste Codepage ist die ASCII-Tabelle, diese umfasst 128 Zeichen. Um länderspezifische Zeichen zu codieren wurden auch andere Codepages definiert, die aber aufgrund der Kompatibilität die ersten 128 Zeichen aus der ASCII-Codierung übernommen und für die Anpassungen lediglich die hinteren 128 Plätze benutzt haben. Diese Zeichensatztabellen wurden zur Identifikation nummeriert.
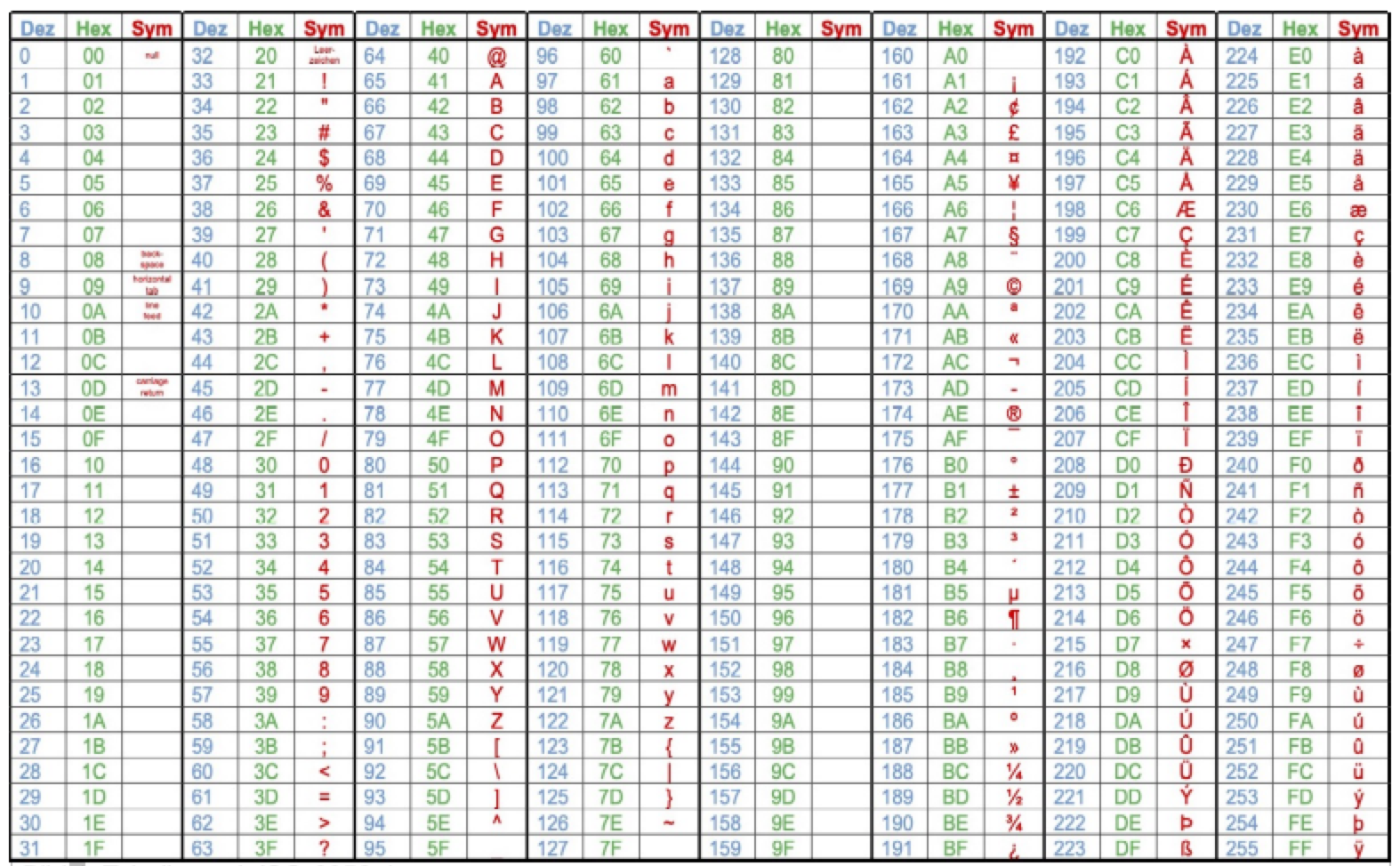
Bildquelle: Tabelle nach ISO-8859-1 von ZPG Informatik [CC BY-SA 4.0 DE], aus 1_hintergrund.odt, bearbeitet
Hauptsächlich benutzt wurde hierbei die Codepage 850 – besser bekannt als DOS-Latin-1. Daneben entwickelte die ISO die Norm 8859 mit 15 verschiedenen Codepages.5
In den ersten 128 Zeichen entsprechen sie der ASCII-Tabelle, die weiteren Zeichen bis Nummer 160 sind nichtdruckbare Steuerzeichen. Dieser Bereich ist bei allen diesen Codepages identisch. Diese Steuerzeichen gehen zumeist noch auf die analoge Schreibmaschine zurück. Bei der „Übersetzung“ von Schreibmaschine in eine digitale Eingabe wurden dabei für sämtliche Tasten ein „Zeichen“ definiert. So hat beispielsweise der Backspace das Steuerzeichen 8.
Die unterschiedliche Verwendung des Blocks für Zeichen ab Index 161 sorgte dafür, dass beim Austausch von Dokumenten in verschiedenen Gebieten – insbesondere z.B. bei der Anzeige im Internet – dazu, dass Sonderzeichen falsch dargestellt wurden, wenn der falsche oder gar kein Zeichensatz angegeben wurde.
Beispiel: Der Umlaut „ö“ wurde in verschiedenen Codepages mit dem Index 246 identifiziert. Wurde eine Webseite ohne Angabe der richtigen Codepage beispielsweise in Griechenland aufgerufen, wurde dort automatisch die griechische Codepage (ISO-8859-7) angenommen. In dieser steht an der Stelle 246 das φ . Somit erschien auf solchen Webseiten dann „Dφner“.
Unicode und Biterweiterung
Im Alltag kam es mit Codepages immer wieder zu oben geschilderten Problemen und des weiteren gibt es auch Sprachen, die nicht mit 256 Zeichen auskommen, da diese nicht alphabetisch sondern lautbasiert aufgebaut sind. Alleine der chinesische Schriftsatz umfasst insgesamt über 100000 Zeichen, von denen immerhin ca. 5000 gebräuchlich sind.
Um diesen Sprachen gerecht zu werden, wurde bereits 1988 ein universeller Zeichensatz vorgeschlagen, der alle weltweit gebräuchlichen Zeichen beinhaltet. Die erste Version von Unicode wurde 1991 veröffentlicht, mit der Version 2 aus dem Jahr 1996 wurde die Anzahl der Zeichen auf die heutige Größe von maximal 1.114.112 erweitert6.
Multibyte Zeichencodierung, UTF-8
4 Byte sind jedoch für die allermeisten Zeichen nicht notwendig. Um nun nicht für jedes Zeichen 4 Bytes „verschwenden“ zu müssen, wird in der Regel für die Darstellung der Unicode-Zeichen eine sogenannte Multibyte-Zeichencodierung verwendet. Hierbei ergibt sich aus der Codierung selbst, wie viele Bytes für ein Zeichen verwendet werden.
Am gebräuchlichsten ist hierbei die UTF-8-Codierung, bei dieser existieren 4 Bereiche:
| Unicode-Bereich | UTF-8-Codierung (binär) | Anzahl der codierbaren Zeichen | |
| 0000 0000 - 0000 007F | 0xxxxxxx | 27 | 128 |
| 0000 0080 - 0000 07FF | 110xxxxx 10xxxxxx | 211 − 27 | 1920 |
| 0000 0800 - 0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx | 216 − 211 | 63488 |
| 0001 0000 - 0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx | 220 | 1048576 |
| Gesamt: | 1114112 | ||
Das erste Bit gibt an, ob es sich bei dem Zeichen um ein Zeichen mit einem Byte (erstes Bit = 0), oder mehreren Bytes (erstes Bit = 1) handelt. Bei einem Zeichen mit nur einem Byte entspricht die Zeichencodierung dem ASCII-Code.
Bei Zeichen mit mehreren Bytes entspricht die Anzahl der führenden 1en der Anzahl der Bytes des kompletten Zeichens. Alle Nachfolgebytes beginnen mit der Bitfolge 10.
Theoretisch kann man so jedoch Zeichen auf unterschiedliche Art darstellen. Beispielweise lässt sich ein „a“ – nach ASCII-code mit den 7 Bit 1100001 codiert – u.a. mit folgenden Bitcodes ausdrücken:
- mit einem Byte: 01100001
- mit zwei Bytes: 11000001 10100001
- mit drei Bytes: 11100000 10000001 10100001
Unterstrichen sind dabei die Steuerbits, der eigentliche Buchstabe „a“ ist fett markiert.
Theoretisch sind diese Darstellungen zwar ebenfalls gültig, jedoch muss nach Definition die kürzeste verwendete Form verwendet werden. Da jedoch alle diese Codierungen das selbe Zeichen beschreiben, muss man bei der maximalen Anzahl der codierbaren Zeichen diese „kürzbaren“ Möglichkeiten abziehen.
Anmerkung: Ebenfalls nach Definition der UTF-8-Codierung kann ein 4 Byte großes Zeichen im ersten Byte nur mit 11110000 bis 11110100 beginnen. Zeichen darüber sind unzulässig.
Mithilfe dieser Codierung ließen sich theoretisch bis zu 8 Byte große Blöcke darstellen. Das erste Byte bestünde dann aus 11111111, die 7 Folgebytes beginnen mit 01. Somit blieben in 7 Bytes jeweils 6 Nutzbits für die Daten, es ließen sich also 242=4.398.046.511.104 Zeichen darstellen. UTF-8 ist jedoch nur für maximal 4 Bytes definiert.
5 Für weitere Informationen und die Unterscheidungen: https://de.wikipedia.org/wiki/ISO_8859
6 32 Bit, abzüglich einiger Steuerbits und Steuerzeichen.
Hintergrundinformationen: Herunterladen [odt][1 MB]
Weiter zu Kompression