Kompression
Einleitung
Begriffe7
- Information: Information umfasst eine Nachricht zusammen mit ihrer Bedeutung für den Empfänger
- Daten: Informationen werden in digitale Daten umgewandelt, um von Maschinen weiterverarbeitet werden zu können.
- Codierung: Wie die Information/Daten dargestellt werden.
- Code: Die (binäre) Darstellung der Daten. Achtung: nicht zu verwechseln mit Verschlüsselung!
- Code-/Wortlänge: die (binäre) Länge eines Codes. Da hier lediglich Texte codiert werden, ist es sinnvoll, den Begriff „Codelänge“ zu verwenden und „Wort(länge)“ komplett zu meiden! Diese Größe werden wir als Vergleichsmaß bei der Komprimierung verwenden.
- Zeichen: ein einzelner Buchstabe der Daten, d.h. des zu codierenden Textes. • Binärbaum: eine Baumstruktur, bei der jeder Knoten genau 2 (Wurzel- bzw. innerer Knoten) oder 0 (Blatt) Kindknoten hat.
- Entzifferbarkeit: Aus einem Code lassen sich eindeutig wieder die Daten/Information herstellen.
- Präfixfreiheit bzw. Fano-Bedingung: kein Code eines beliebigen Zeichens ist der Anfang des Codes eines anderen Zeichens.
Ziel
- 3.3.1.1 (6) Merkmale von Codierungen (unter anderem Entzifferbarkeit, Präfixfreiheit, feste/variable Bitlänge) erläutern
- 3.3.1.1 (7) das Huffmanverfahren als Beispiel für ein verlustfreies Datenkompressionsverfahren erläutern und die Codierung durch Erzeugung eines Huffmanbaums sowie Decodierung von Hand durchführen.
Didaktische Anmerkungen
- Als Einstieg ggf. zuerst einen Schätzwert abgeben lassen, wie viel unkomprimiertes Videomaterial sich auf eine BluRay speichern ließe.
- Informationsgehalt nach Shannon ist nicht Inhalt des Bildungsplanes!
- Hier wird das LZW-Verfahren zunächst mit einer fest definierten Codelänge vorgestellt. Es funktioniert auch mit einer variablen Bitlänge, die am Ende als Ausblick dargestellt wird.
Einführung
Bei den heutigen Speicherkosten könnte man sich immer mehr fragen, ob denn Kompression überhaupt noch notwendig ist. Die Antwort lautet ganz klar „JA“, denn das lässt sich mithilfe eines einfachen Rechenbeispiels ganz einfach zeigen:
Angenommen wir wollen einen Film auf eine BluRay mit 50GB Speicherplatz brennen. (Alternativ könnte man hier auch eine Festplatte mit z.B. 4TB Speicherplatz nehmen). Wie lang darf ein Film in 4K-Auflösung, 24Bit Farbtiefe und 60Hz Bildrate dafür höchstens sein?
- 4K-Auflösung: 3840x2160 = 8.294.400 Pixel
- jeweils 24 Bit: = 24.883.200 Byte = 24300 kiB = 23,73 MiB pro Bild
- 60 Bilder pro Sekunde: = 1.423,83 MiB/s = 1,39 GiB pro Sekunde
Das würde bedeuten, auf eine BluRay-Disk passen lediglich knapp 36 Sekunden unkomprimiertes Bildmaterial. Auf eine 4TB-Festplatte lediglich eine dreiviertel Stunde! Insbesondere wenn man dann auch Filme über das mobile Datennetz anschaut, sieht man an dieser Rechnung sehr eindrücklich, dass es auch in der heutigen Zeit noch stark auf gute Kompression ankommt.
Informationsgehalt
Der Informationsgehalt einer Nachricht ist eine statistische Größe. Sie wurde von Claude Shannon erstmals formalisiert8 . Der Informationsgehalt eines einzelnen Zeichens x ist definiert als:
I(x)=−logw(px)
Wobei px die Auftrittswahrscheinlichkeit des Zeichens x bezeichnet und w die Mächtigkeit des Zielalphabets. Bei einer binären Codierung ist also w = 2.
Vereinfacht gesagt: je öfter ein Zeichen auftritt, desto weniger Information steckt ist diesem.
Beispiel: in der deutschen Sprache kommen besonders häufig z.B. Vokale vor. Diese werden aber hauptsächlich als Bindeglieder zwischen Konsonanten benutzt. Die eigentliche Information steckt im Wesentlichen in den Konsonanten. Dies kann man selbst ausprobieren, indem man aus einem Text zunächst alle häufigen Buchstaben entfernt und im zweiten Schritt nur diese übrig lässt. Im Beispiel wurden die Vokale und zusätzlich die Buchstaben „m“ und „s“ entfernt, damit bei beiden Versionen ungefähr ähnlich viele Buchstaben übrig bleiben:
| e eie so sae u a u i Es is e ae mi seiem i E a e ae o i em Am E ass i sie e i am |
Wr rtt pt drch Ncht nd Wnd? t dr Vtr t n Knd; r ht dn Knbn whl n d r, r ft hn chr, r hält hn wr. |
Man kann daran sehen, dass beim linken Text kein Inhalt erkennbar, der rechte Text aber mit etwas Mühe lesbar ist. Der Vollständigkeit halber noch der komplette Text:
Wer reitet so spaet durch Nacht und Wind?
Es ist der Vater mit seinem Kind;
Er hat den Knaben wohl in dem Arm,
Er fasst ihn sicher, er hält ihn warm.
Reduktion der Datenmenge bei Erhaltung der Information
Ziel der Kompression ist also, die Codierung dahingehend anzupassen, dass die Datenmenge verkleinert wird und dabei keine Information verloren geht. Das kann auf unterschiedliche Arten passieren:
- Entropiecodierung: Optimierung, so dass oft vorkommende Zeichen weniger Speicherplatz verwenden als weniger oft vorkommende Zeichen. → Huffman-Codierung
- Wörterbuchcodierung: Wiederholende Zeichenfolgen in einem Wörterbuch speichern und darauf verweisen. → LZW-Codierung
- Lauflängencodierung: mehrfach nacheinander vorkommende Zeichen(folgen) werden abgekürzt.
Entzifferbarkeit, Fano-Bedingung, Präfixfreiheit
Eine Codierung heißt eindeutig entzifferbar, wenn für jeden Code nur eine eindeutige Nachricht existiert. Das bedeutet, aus einem Code darf – auch ohne Zuhilfenahme von Semantik und Kontext – lediglich eine mögliche Nachricht entstehen.
Beispiel für nicht eindeutig entzifferbar: Morsecode:
- ∙ − − ∙ ∙ ∙ − ∙ − ∙ = ABC
- ∙ − − ∙ ∙ ∙ − ∙ − ∙ = EGFN
Bei Morsecode benötigt man deshalb neben den beiden Zeichen kurz und lang auch noch die Pause, um einzelne Buchstaben voneinander abgrenzen zu können.
Das Problem hierbei lässt sich direkt erkennen, da schon die Codierung für A = ∙ − bereits eine Zusammensetzung aus E = ∙ und T = − sein könnte. Der Beginn der Codierung für A entspricht der Codierung von E.
Verallgemeinert kann man deshalb sagen: damit eine Codierung entzifferbar ist, darf kein Code eines Zeichens identisch mit dem Anfang des Codes eines anderen Zeichens sein. Man spricht deshalb auch von Präfixfreiheit, bzw. der sogennannten Fano-Bedingung.
Huffman-Codierung: Einführung9
Die Huffman-Codierung funktioniert prinzipiell auch mit Binärdaten, zum besseren Verständnis bzw. Übersichtlichkeit wird das Verfahren hier lediglich mit Texten vorgestellt.
Formal hantieren wir also mit:
- Die Länge des Textes umfasst M Zeichen, davon n unterschiedliche Zeichen.
- Einzelne Buchstaben des Textes. Allgemein nennt man diese „Symbole“ und bezeichnet diese mit s1, s2,...,sn, Man betrachtet dabei nur Symbole, die im Text wirklich auftreten. Bei Binärdaten würde man z.B. einzelne Bytes als Symbole nutzen.
- Die Wahrscheinlichkeit pi eines Symbols im Text berechnet man mit
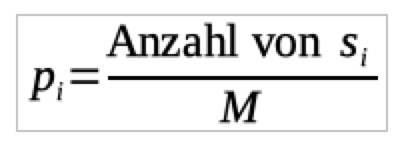
- Die Wortlänge eines Symbols si wird mit li bezeichnet.
- Die durchschnittliche Wortlänge ergibt sich dann aus
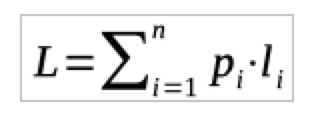
Ziel der Kompression ist, diese durchschnittliche Wortlänge zu minimieren. Man kann sofort erkennen, dass dieses Optimum genau dann erreicht wird, wenn die häufiger vorkommenden Buchstaben (pi also größer) eine kürzere Wortlänge bekommen (li also kleiner).
Sortiert man die Symbole s1, s2,...,sn aufsteigend nach Häufigkeit, dann gilt p1≤ p2≤ ... ≤ pn. Dann soll gelten l1≥ l2≥ ... ≥ ln.Huffman-Codierung: Algorithmus
Um diese Bedingungen zu erreichen baut man den Code für die einzelnen Zeichen von hinten her auf. Man fasst immer die zwei Symbole mit der geringsten Häufigkeit zu einem neuen Symbol zusammen. Grafisch kann man sich das als Binärbaum vorstellen, der von den Blättern her zur Wurzel „wächst“.
Beispiel:10 Wir betrachten die Buchstaben-/Symbolfolge „ADBCBDBCBD“
- Wir zählen die einzelnen Symbole:
- Die zwei Symbole mit den wenigsten Vorkommen („A“ und „C“) fassen wir zu einer Gruppe zusammen:
- Die neue Gruppe hat also eine absolute Häufigkeit von 3 und wird als gesamtes wieder in die Symbolliste aufgenommen. Im folgenden werden also nur die blauen Symbole bzw. Symbolgruppen betrachtet.
- Erneut nehmen wir die zwei (blauen) Symbole mit der kleinsten Häufigkeit (die eben erzeugte Gruppe „AC“ sowie „D“)
- Wiederhole den Vorgang so oft, bis nur noch eine einzelne Gruppe mit allen vorhandenen Symbolen existiert:
- Erzeuge den Binärcode für jedes einzelne Symbol, indem der Pfad von oben nach unten durchgegangen wird. Für jeden Weg in die eine Richtung hänge eine „0“ an den Pfad an, für jeden Weg in die andere Richtung eine „1“11 . Daraus ergibt sich:


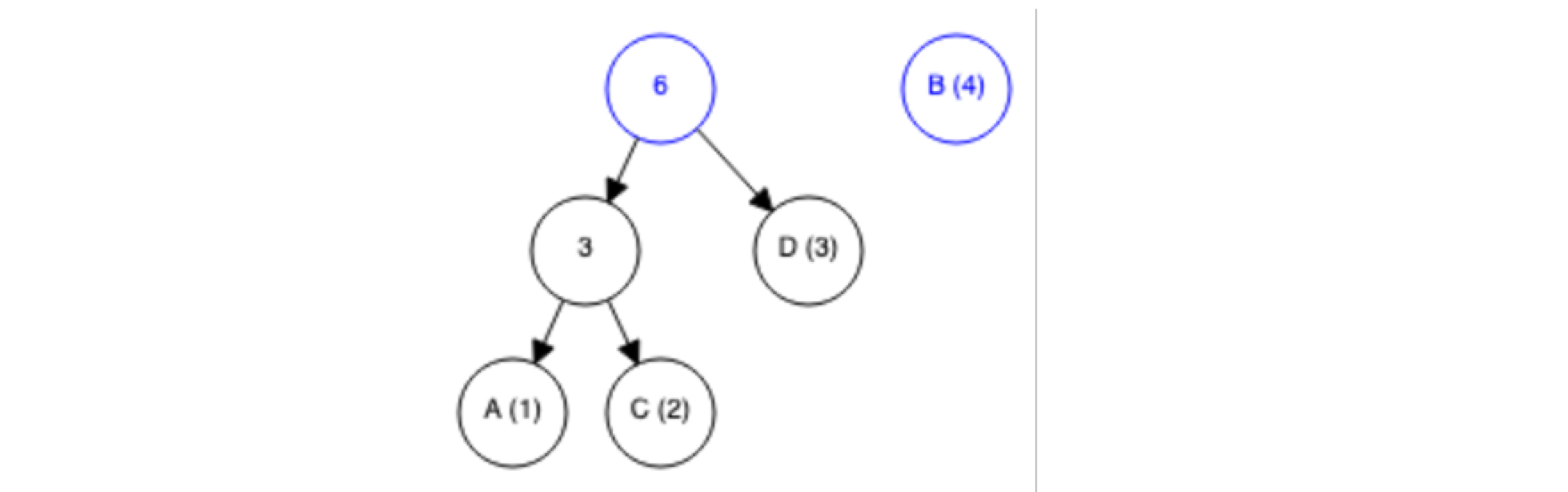
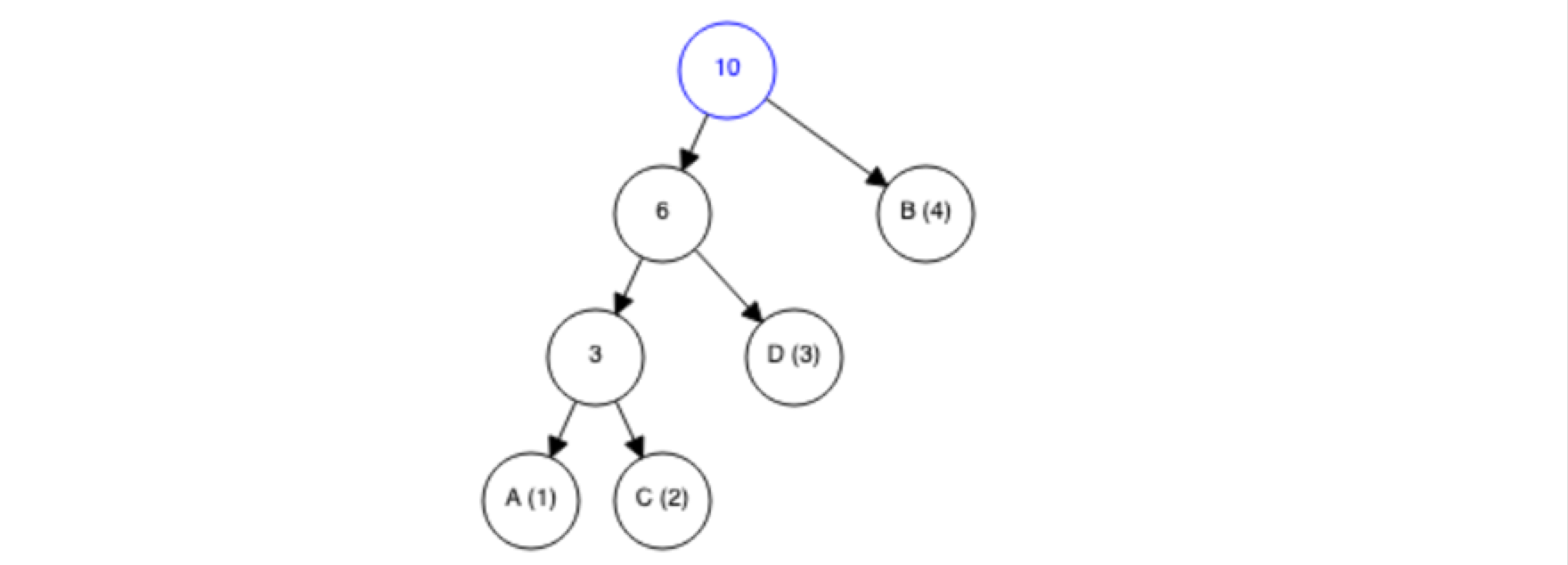

Dadurch, dass nur an den Blättern des Binärbaums die Symbole vorkommen, ist dadurch auch die Präfixfreiheit des Codes gegeben. Außerdem sieht man daran direkt, dass durch den Baum auch das Optimum für die Codelänge gegeben ist, denn den weniger oft vorkommenden Symbolen werden automatisch längere Binärcodes zugewiesen.
Für die Codierung des Textes „ADBCBDBCBD“ werden die Binärcodes jedes einzelnen Symbols hintereinandergesetzt und man erhält:
0000110011011001101
Bei der Decodierung geht man entsprechend den Bits den Weg ausgehend von der Wurzel entlang des Baumes. Ist man an einem Blatt mit einem Symbol angekommen, so beginnt man wieder von vorne:

Wörterbuchverfahren: Einführung
Wörterbuchverfahren nutzen zur Kompression Redundanz aus. Sich oft wiederholende Wörter und Symbolfolgen werden in einem Wörterbuch gespeichert und bei der Codierung auf diese Einträge referenziert. Man unterscheidet dabei zwischen Verfahren mit statischen und solchen mit dynamisch erzeugten Wörterbüchern. Bei dynamischen Verfahren wird das Wörterbuch bei der Kompression bzw. Dekompression automatisch befüllt, wodurch man dieses nicht separat speichern muss und damit weiterer Speicherplatz eingespart werden kann.
Lempel-Ziv-Welch: LZW-Verfahren
Um ein dynamisches Wörterbuch zu erzeugen und darauf referenzieren zu können, benötigt man pro Symbol bzw. Referenz mehr als 8 Bit. Üblicherweise verwendet man 12 Bit. Das Wörterbuch umfasst also maximal 212=4096 Einträge, wovon die ersten 256 Symbole den Bytes selbst von 0016 bis FF16 entsprechen.
Die zu komprimierenden Daten können hierbei beliebige Binärdaten sein, zur besseren Verständlichkeit und Übersichtlichkeit verwenden wir hier lediglich Text.
Soll ein Text (oder andere Daten) komprimiert werden, so sucht man – ausgehend von der jeweils aktuellen Stelle – die längstmögliche Symbolfolge im Wörterbuch. Zu Beginn ist das jeweils nur ein einzelner Buchstabe. Anschließend wird die gefundenen Symbolfolge und das nachfolgende Symbol als neuer Eintrag in das Wörterbuch eingetragen.
Beispiel: Der Text „BABAABAAA“ soll mithilfe des LZW-Verfahrens komprimiert werden. Man startet mit einem Wörterbuch, in dem lediglich die Symbole von 0 bis 255 belegt sind.
| Noch zu bearbeitende Zeichenkette | Gefundener Eintrag | Ausgabe 12Bit, Hexadezimal | Neuer Wörterbucheintrag |
| BABAABAAA | B ← 04216 | 04216 | BA → 10016 |
| ABAABAAA | A ← 04116 | 04116 | AB → 10116 |
| BAABAAA | BA ← 10016 | 10016 | BAA → 10216 |
| ABAAA | AB ← 10116 | 10116 | ABA → 10316 |
| AAA | A ← 04116 | 04116 | AA → 10416 |
| AA | AA ← 10416 | 10416 |
Die Zeichenfolge wird also zur Bitfolge (Hexadezimal): 042041100101041104
LZW: Dekompression
Bei der Dekompression werden jeweils 12Bit-Blöcke eingelesen. Das Wörterbuch ergibt sich aus dem ersten Zeichens des aktuellen Eintrags, welcher an den zuletzt gefundenen Eintrag angehängt wird:
| Aktueller 12Bit-Block | Gefundener Eintrag, erster Buchstabe | Neuer Wörterbucheintrag | Ausgabe |
| 04216 | B | B | |
| 04116 | A | BA → 10016 | A |
| 10016 | BA→ B | AB → 10116 | BA |
| 10116 | AB→ A | BAA → 10216 | AB |
| 04116 | A | ABA → 10316 | A |
| 10416 | AA→ A | AA → 10416 | AA |
Ein Sonderfall ergibt sich bei der Dekompression im letzten Schritt. Wenn eine Zeichenfolge mehrfach hintereinander im Ursprungstext auftritt, so kann es vorkommen, dass bei der Dekompression auf einen Wörterbucheintrag verwiesen wird, der noch nicht existiert. Dann gilt: der „gefundene“ Eintrag entspricht dem vorherigen Eintrag + dem ersten Buchstaben des vorherigen Eintrags.
Es empfiehlt sich, diesen Sonderfall anfangs in der Schule zu meiden.
7 Vgl. Aufbaukurs Informatik
8 Der mathematische Informationsgehalt nach Shannon ist nicht Teil des Bildungsplanes.
9 Nach https://www.swisseduc.ch/informatik/daten/huffmann_kompression/docs/huffman.pdf
10https://people.ok.ubc.ca/ylucet/DS/Huffman.html
11 Anmerkung: hier wurde einheitlich für die Wege nach links die „0“, nach rechts die „1“ gewählt. Man muss dies jedoch innerhalb des Baumes nicht einheitlich machen!
Hintergrundinformationen: Herunterladen [odt][1 MB]
Weiter zu Hashing