Historische Entwicklung der Rechenmaschinen
Stellt man sich einen hart arbeitenden Menschen etwa zur Zeit des 17. oder 18. Jahrhunderts vor, dann denkt man zumeist an körperlich hart arbeitende Männer, Frauen und Kinder. Es gab aber schon damals eine ganz andere „harte Arbeit“, die jedoch eher „geistig“ hart zu nennen ist: Das Rechnen per Hand.
Noch im Mittelalter galt Schreiben und Rechnen als weibisch, mit Gründung der ersten Universitäten aber mussten Männer die Rechenarbeit übernehmen, denn Frauen wurden wie bekannt an den Universitäten nicht zugelassen.
Ende des 18. Jahrhunderts gab es die ersten „Rechner“ von Beruf, Menschen also, die als Auftragsarbeit zu rechnen hatten oder aber mit der Lösung eines numerischen Problems beauftragt wurden. Solche Menschen wurden im angelsächsischen Bereich tatsächlich „Computer“ genannt. Es standen ihnen zu dieser Zeit aber immerhin schon einige Hilfsmittel zur Verfügung. Dennoch muss man sich deren Arbeit als sehr zeitraubend und anstrengend vorstellen. Ein Beispiel:
Lalande arbeitete danach als Assistent von Alexis-Claude Clairaut an einer besseren Bahnberechnung des Halleyschen Kometen, was zu einer Beschäftigung (wie auch bei Clairaut, d'Alembert und Euler) mit dem Dreikörperproblem führte. Mit Methoden Clairauts konnte Lalande erfolgreich die Bahnstörungen des Kometen durch große Planeten berechnen. Unterstützt wurde er dabei in der umfangreichen Rechenarbeit durch Nicole-Reine Lépaute (1723–1788), deren Beitrag wie der anderer damaliger Mathematikerinnen, die für ihre männlichen Kollegen „Rechenarbeit“ ausführen durften, weitgehend ignoriert wurde. Lalande würdigte ihre Arbeit so:
Sechs Monate lang rechneten wir von morgens bis nachts .. Die Hilfe Mme. Lépautes war so, dass ich ohne sie die enorme Arbeit überhaupt nicht hätte in Angriff nehmen können. Es war notwendig, die Distanz der beiden Planeten Jupiter und Saturn zum Kometen separat für jeden aufeinanderfolgenden Grad über 150 Jahre hinweg zu berechnen.1
So ist es verständlich, dass schon sehr früh der Wunsch aufkam, die stumpfsinnige Rechenarbeit von einer Maschine erledigen zu lassen.
Einfache mechanische Rechenmaschinen
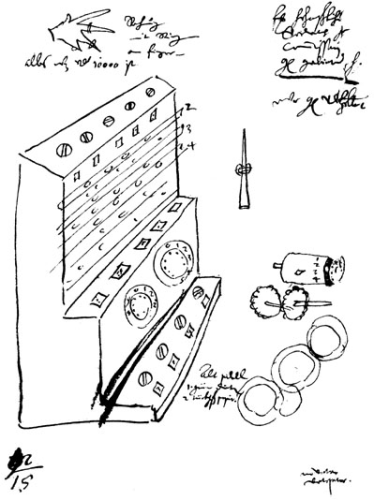
Rechenmaschine von Wilhelm Schickard (Originalzeichnung), Rechenmaschine_wilhelm_schickard.png von MichaelFrey [Public Domain] via Wikimedia Commons
Bereits 1623 beschrieb Wilhelm Schickardt (leider sehr knapp) in einem Brief an Kepler, wie seine Additions-Maschine funktioniert. (Das Bild rechts ist eine Zeichnung, die er zur Erläuterung beigefügt hatte!) Sie bestand aus einem Addier- und Subtrahierwerk und ließ sogar Multiplikation und Division nach der Methode der „Napierschen Rechenstäbchen“ zu. Leider verbrannte das Original.
Die 1645 von Blaise Pascal vorgestellte Rechenmaschine Pascaline war eine reine Addiermaschine. Er entwickelte sie für seinen Vater, einen Steuerbeamten.
Unter den vier „Species“ (erstmals 1200 im Codex der Klosters Salem erwähnt) verstand man Addition, Subtraktion, Multiplikation und Division. 1673 stellte Leibniz eine Vier-Species-Maschine mit Staffelwalzen-Prinzip vor. Das untere Zahnrad (die Staffelwalze) im Bild unten links dient als Antrieb und kann in Richtung der Walzenachse verschoben werden. Bei Einstellung der 0 befindet sich das obere Zahnrad ganz links, bei 9 entsprechend ganz rechts. Bei einer vollen Umdrehung der Staffelwalze wird so das obere Zahnrad zwischen 0 und 9 Zähnen weitergedreht.

Staffelwalze, Staffelwalzeprinzipbha.jpg von Barbarah [CC BY-SA 3.0] via Wikimedia Commons

Leibniz Rechenmaschine (Nachbau), Leibnitzrechenmaschine.jpg von Kolossos [CC BY-SA 3.0] via Wikimedia Commons
Programmierbare mechanische Rechenmaschinen
Mit den oben genannten ersten mechanischen Rechenmaschinen war nur eine teilweise Arbeitsentlastung möglich, denn sie erlaubten ja immer nur genau einen Rechenvorgang. Eine weit größere Arbeitsersparnis wäre es, wenn die Maschine eine Reihe von festgelegten Rechnungen durchführen könnte. Die Krönung allerdings wäre eine Maschine, bei der selbst diese Reihenfolge variabel gestaltet werden könnte, wenn sie also „programmiert“ werden könnte!
Ganz futuristisch war dieser Gedanke selbst Anfang des 19. Jahrhunderts keinesfalls. Denn schon 1805 stellte Joseph-Marie Jacquard einen automatischen Webstuhl vor, der durch Lochkarten gesteuert wurde. Das „Web-Programm“ war (auf Lochkarten) gespeichert. Man kann diese Maschine durchaus als Vorläufer programmierbarer Rechenmaschinen sehen, auch wenn sie selbst nicht rechnen konnten, führen sie doch eine Art „Programmspeicher“ ein.

Hollerith Zählmaschine, HollerithMachine.chm.jpg von Adam Schuster [CC BY-SA 2.0] via Wikipedia
Diese Maschine plante 1822 als erster Charles Babbage. Sie war zu seinen Lebzeiten leider nie verwirklicht. Dennoch gebührt ihm großer Ruhm, denn seine Idee nutzte 1886 Hermann Hollerith, um die erste funktionsfähige Zähl-Maschine für Massen-Daten-Eingabe mit Lochkarten zu verwirklichen. Sie diente zur Auswertung der Volkszählung in den USA. Mit Stecktafeln konnte man bestimmte Arbeitsprogramme auswählen.
Digitale Rechenmaschinen: Z3
Konrad Zuse schließlich baute 1941 die erste funktionsfähige universell programmierbare Rechen-Maschine der Welt. Sie bestand aus 2000 Relais und konnte 64 Worte je 22 Bit speichern. Eine Multiplikation erledigte sie in 3 Sekunden (!!). Er führte mit ihr die binäre Gleitkomma-Arithmetik ein.

Nachbau Zuse Z3, Z3_Deutsches_Museum.JPG von Venusianer [CC BY-SA 3.0] via Wikimedia Commons
Seine Maschine, die 1943 bei einem Bombenangriff zerstört wurde, gilt als erster Computer der Welt. (In den USA sieht man die Sache etwas anders: Für sie ist die ENIAC von 1946 der erste Computer der Welt!).
Bei allem Respekt vor Zuses Leistung, eine wünschenswerte Möglichkeit bietet die Z3 leider nicht: Man kann keine „bedingten Sprünge“ realisieren, das sind Sprünge, die von den eingegebenen Daten abhängen. Das Rechenwerk und das Steuerwerk der Z3 sind streng getrennt. Somit können die Daten nicht auf die Steuerung einwirken.
Von-Neumann-Architektur
Aus heutiger Sicht mag es seltsam erscheinen, dass es bis 1945 gedauert hat, bis erstmals durch John von Neumann der Gedanke veröffentlicht wurde, dass nämlich Daten und Steuerung nicht getrennt werden müssen, um eine brauchbare Rechen-Maschine zu konstruieren. Daten und Programm verwenden den gleichen Speicher und sind äußerlich nicht zu unterscheiden.
Obwohl dieses Konzept in den anschließenden Kapiteln noch ausführlich behandelt wird, hier schon einmal ein Überblick:
Ein Rechner nach der Von-Neumann-Architektur besteht aus vier grundlegenden, miteinander verbundenen Komponenten:
- Steuerwerk (in der CPU)
- Rechenwerk (Arithmetic Logic Unit (ALU) in der CPU)
- Speicher
- Ein-/Ausgabewerk
Diese Komponenten haben folgende Aufgaben:
-
Das Steuerwerk holt die Befehle und Daten aus dem Speicher, dekodiert diese und führt die gewünschten Operationen dann sequentiell aus.
-
Das Rechenwerk führt grundlegende mathematische und logische Operationen aus.
-
Der Speicher ist an jeder beliebigen Stelle direkt les- und schreibbar und dient dazu, Befehle und Daten zu speichern. Dabei sind Befehle und Daten gleichwertig und beide binär codiert. Der Speicher ist in gleichgroße Einheiten eingeteilt (Bytes), die fortlaufend durchnummeriert werden (Adressierung). Diese Adresse dient zum Zugriff auf eine Speicherzelle. Ein Programm liegt mit seinen Daten hintereinander im Speicher, es wird dann sequenziell abgearbeitet. Durch Sprungbefehle kann von dieser strengen Reihenfolge abgewichen werden.
-
Das Ein-/Ausgabewerk sorgt für die Eingabe und Ausgabe der Daten.
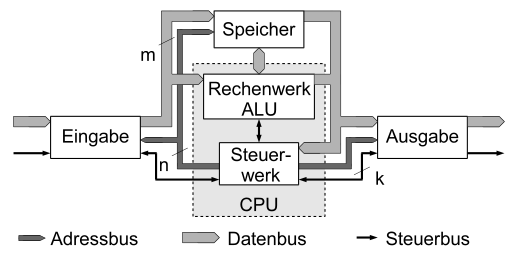
Von-Neumann-Architektur, "von Neumann" Architektur de.svg von Medvedev [CC BY-SA 3.0] via Wikimedia Commons
Alle diese Zugriffe werden über ein Bussystem abgewickelt, das die Kommunikation zwischen Prozessor, Arbeitsspeicher und auch den Peripheriegeräten regelt.
Rechenwerk und Steuerwerk arbeiten sehr eng zusammen und werden als Einheit betrachtet, die mit dem Begriff Prozessor bezeichnet wird. Wenn als Speicher der im Prozessorgehäuse untergebrachte sehr schnelle Zwischenspeicher namens Cache gemeint ist, dann heißen alle drei zusammen CPU (= Central Processing Unit).
Der enorme Vorteil dieser neuen Architektur ist, dass nun die Programme leicht veränderbar im Arbeitsspeicher gehalten werden können. Ein Umstecken von Kabel zur Programmierung oder eine externe Speicherung auf Lochkarten ist nicht mehr notwendig.
Der wichtigste Nachteil der von-Neumann-Rechner ist die begrenzte Datengeschwindigkeit zwischen Prozessor und Speicher. Mit den langsamen Prozessoren in der Anfangszeit der Computer war dies kein Problem. Heutzutage ist die Prozessorgeschwindigkeit der Zugriffsgeschwindigkeit auf den RAM deutlich überlegen. Man spricht daher vom von-Neumann-Flaschenhals. Um diese Schwachstelle etwas abzumildern, bauen die Chiphersteller inzwischen sehr schnelle Zwischenspeicher (Caches) direkt an den Prozessor an. Diese schnellen Speicher sind sehr teuer. Und dennoch lohnt der Aufwand: Über die Geschwindigkeit eines Rechners entscheidet inzwischen weniger die Taktrate (sie liegt bei den meisten PCs heute bei knapp 3 GHz) als vielmehr die Größe der verschiedenen Caches. (Weitere Informationen zum Thema: CPU-Cache)
Von-Neumann-Computer: Commodore 64 und andere

C64, Commodore64withdisk.jpg von PrixeH [CC BY-SA 3.0] via Wikimedia Commons
1982 kam in den USA der neben stehend abgebildete C64 (in Deutschland „Brotkasten genannt) heraus, der mit dem 6510-Prozessor arbeitete. Das C stand für Consumer, die 64 verdankt er der Tatsache, dass der beschreibbare Arbeitsspeicher, kurz der RAM (Random Access Memory) 64 KByte groß war.
Zum Vergleich: Heutige PCs haben ca. 100000 mal so viel RAM. Der Prozessortakt betrug knapp ein MHz, heute sind die Prozessoren 2000 mal so schnell. Seine Architektur entspricht weitgehend der originalen Von-Neumann-Architektur.
Eine Festplatte hatte der C64 noch nicht. Zum dauerhaften Speichern von Daten und zum Laden eines Programms, verwendete man Disketten. Sie hatten eine Kapazität von zweimal 165 KByte (Vorder- und Rückseite). Heute hat eine durchschnittliche Festplatte einige Millionen mal so viel! Eine Besonderheit des Rechners ist sein ROM-Speicher (Read Only Memory) von 20 KByte. Lediglich 7 KByte wurden für das Betriebssystem benötigt. Zwischenfrage: Wie viel KByte benötigt das Betriebssystem Windows 10? Weitere 9 KByte waren für den von der Firma Microsoft entwickelten BASIC-Interpreter reserviert.
Ein Vorteil hatte diese Technik mit Sicherheit: Viren und sonstige Malware konnten zumindest dem Betriebssystem nichts anhaben! Ein zweiter Vorteil kommt hinzu: Durch die eingeschränkten Ressourcen waren die Entwickler gezwungen sehr sparsam mit dem Speicherplatz umzugehen und zeitaufwendige Rechnungen so zu vereinfachen, dass der C64 in vernünftiger Zeit damit fertig werden konnte. Dadurch haben sie es tatsächlich geschafft, dass man nach 10 Minuten Ladezeit, sogar Schach gegen die Maschine spielen konnte. Und wer kein geübter Spieler war, verlor ohne Weiteres gegen die Maschine.
Mit dem kostenlosen Emulator VICE2 kann man, nach Einstellung der Sprache und der deutschen Tastatur die Anfänge des PCs nochmal nachvollziehen.
Harvard-Architektur
Nachteil der Von-Neumann-Architektur ist, wie schon erwähnt, dass es nur einen Datenbus und einen Adressbus gibt. Die Programmausführung wird verlangsamt, denn während die Daten gelesen und geschrieben werden, kann nicht schon der nächste Befehl über den Datenbus geholt werden. Daher ist eine gleichzeitige Verarbeitung von Daten und Befehlen nicht möglich.
Daher hat sich neben der Von-Neumann-Architektur eine zweite Architektur durchgesetzt: Die Harvard-Architektur (Howard Aiken an der Universität Harvard) erinnert zunächst an die Zuse Z3, da Daten und Programme in zwei getrennten Bereichen gespeichert werden. Es gibt daher auch zwei getrennte Busse für Daten und Programm. Die Programmausführung wird durch die gleichzeitige Befehls- wie Datenverarbeitung deutlich beschleunigt. Bedingte Sprünge können aber im Gegensatz zur Z3 trotzdem realisiert werden, da die Daten einen Einfluss auf das Steuerwerk haben können.
Daneben gibt es noch ein Argument, auf die Von-Neumann-Architektur zu verzichten. Wenn es um die Sicherheit geht, wird der ursprüngliche Vorteil des Von-Neumann-Konzepts zum Nachteil: Hier kann Programm-Code anderen Programm-Code überschreiben. Prinzipiell ist ein solch „selbstmodifizierender Code“ möglich, weil das „Programm“ im vom Programm veränderbaren Speicher liegt. Dies ist bei der Harvard-Architektur nicht möglich, da der Programm-Speicher während des Programmablaufs nicht verändert werden kann.
Moderne Architekturen
Moderne Prozessoren (z.B. Intel Core-Technologie) bestehen oft aus einer Mischform beider Architekturen. Intern besitzen sie zwei getrennte Bus-Systeme für Daten und Befehle, die mit dem L2-Cache kommunizieren. Dieser L2-Cache kommuniziert dann über einen gemeinsamen Bus mit dem Arbeitsspeicher. Um die Verarbeitungsgeschwindigkeit zu erhöhen, versucht man Daten und Befehle schon bevor sie benötigt werden in den L2-Cache zu übertragen (Prefetch). Dazu muss der Prozessor „raten“, welche Daten benötigt werden könnten.
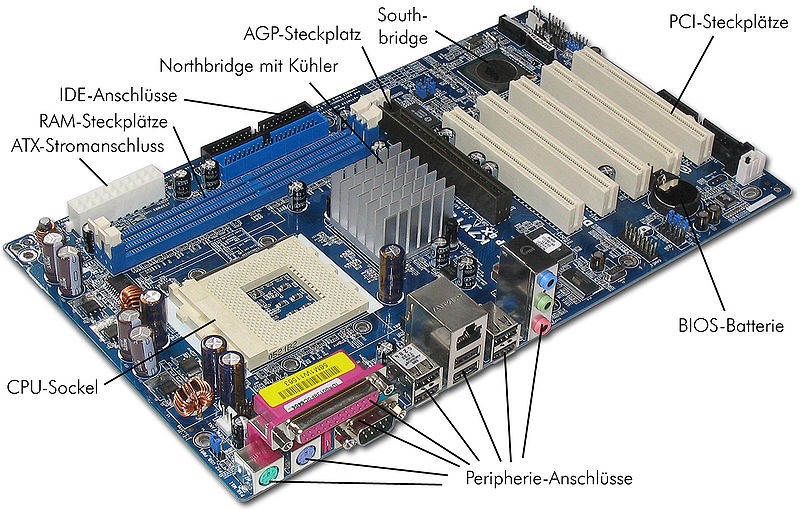
ASUS Rock K7, ASRock_K7VT4A_Pro_Mainboard_Labeled_German.jpg von Darkone [CC BY-SA 2.5] via Wikimedia Commons
Die Registerbreite wurde von anfangs 4 Bit auf 64 Bit erhöht. Dadurch wurden immer mehr Transistoren verarbeitet. Heutige Prozessoren (wie etwa der Core i7) haben fast eine Milliarde Transistoren! Weitere Beschleunigung erreichte man durch stetige Erhöhung der Taktfrequenz. Oberhalb von 4 GHz wurde die entstehende Abwärme so groß, dass eine weitere Erhöhung nicht mehr sinnvoll war.
Weitere Geschwindigkeitsvorteile werden nun durch die Erhöhung der Anzahl der Rechenwerke (=Prozessorkerne) erreicht. Im Jahr 2005 kamen die ersten Doppelkern-Prozessoren (DualCore) auf. Anfang mussten beide Prozessor-Kerne auf einen gemeinsamen Cache-Speicher zugreifen. Zwei Jahre später gab es schon 4- und 6-Kern-Prozessoren3 mit jeweils eigenem Cache.
Mehrere Kerne können nun parallel Daten bearbeiten. Zwei wesentliche Techniken haben sich durchgesetzt:
-
SIMD (Single Instruction, Multiple Data)
Mit dieser Technik wird ein Befehl gleichzeitig auf eine Vielzahl gleichartiger Daten angewandt. Es gibt mehrere Recheneinheiten und eignet sich vor allem für hochgradig parallele Probleme. Echte Vorteile bringt die Technik bei Bild- und Multimediaverarbeitung. Heutzutage haben die meisten Prozessoren SIMD auf die eine oder andere Art und Weise (MMX, SSE, etc.) zur Beschleunigung der Grafikausgabe (besonders bei 3D-Spielen).
-
MIMD (Multiple Instruction, Multiple Data)
Diese Technik entspricht dem, was man sich am ehesten unter parallelem Rechnen vorstellt: Man kann verschiedenen Befehle gleichzeitig auf unterschiedliche Daten anwenden. So gut wie alle Supercomputer/Cluster und die meisten der heutzutage vorhandenen Mehrkern-Prozessoren fallen in diese Kategorie. Für das Steuerwerk ist es gar nicht so einfach, die Befehle eines Programms sinnvoll auf die verschiedenen Kerne zu verteilen, wenn das Programm nicht von vornherein daran angepasst ist.
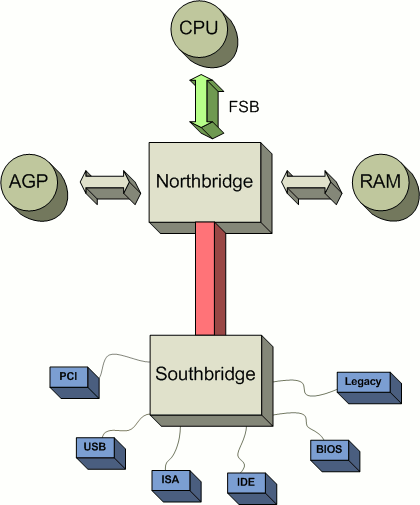
Chipsatz, Schema_chipsatz.png von Alexander Taubenkorb [CC BY-SA 3.0] via Wikimedia Commons
Die Steuerung des Bussystems ist heutzutage meist in zwei separaten Chips – der North- und der Southbridge – realisiert. Die Northbridge befindet sich nahe am Prozessor und regelt die Kommunikation mit Geräten, die sehr schnell arbeiten und einen hohen Datendurchsatz benötigen (z.B. Grafikkarte oder Arbeitsspeicher). Sie hat daher eine hohe Bandbreite und arbeitet mit einer entsprechend hohen Taktrate (Front Side Bus (FSB)) und muss aus diesem Grund oft auch gekühlt werden. Der Prozessortakt ist immer ein Vielfaches des FSB-Taktes. Also Prozessortakt = FSB * Faktor. Eine beliebte Methode, den Rechner um einige Ticks schneller zu machen, war, diesen Faktor zu erhöhen. Heute gibt es nur noch wenige Motherboards, die diesen direkten Eingriff erlauben. Was allerdings noch sehr oft geht, ist die Höhe des FSB-Taktes zu verändern. Damit wächst ja der Prozessortakt automatisch. Allerdings erhöht man damit auch die Taktrate zwischen allen anderen Bauteilen, wie etwa dem RAM und der Northbridge, denn zumeist ist auch deren Taktgeschwindigkeit vom FSB abhängig. Die Northbridge ist auch mit der Southbridge verbunden, an der sich Steckplätzen für weitere Komponenten befindet, die keine so hohe Datenrate benötigen.
Bei neuere Prozessorgenerationen (Stand 2019) ist die Northbridge direkt im Prozessor integriert, was die Zugriffsgeschwindigkeit weiter erhöht. Auch die anderen Bussysteme sind in ständiger Weiterentwicklung. Es lohnt aber ein Blick auf ein Mainboard, auf dem die Datenleitungen gut erkannt werden kann. Man sieht, dass der Arbeitsspeicher sehr nah am Prozessor sitzt und mit zahlreichen Leitungen verbunden ist.
Zusatzaufgabe
Im folgenden Bild ist ein zwar nicht aktuelles aber neueres Motherboard (2005) dargestellt. Die beiden Komponenten, die im Bild oben nicht zu sehen sind oder die es noch nicht gab, sind beschriftet. Zu sehen sind hier auch der Prozessor- und die Chipsatzkühler. Zwei RAM-Bausteine sind ebenfalls eingesteckt.
Versuchen Sie im Bild oder besser noch auf einem realen Motherboard so viele Komponenten wie möglich zu identifizieren. Verwenden Sie dabei Abbildung 11 und/oder das Internet. Weshalb benötigt dieses Motherboard keinen AGB-Steckplatz (Accelerated Graphics Port) mehr für die Grafikkarte? Was versteht man unter PCIe-Lanes?

ASRock A790GXH Motherboard, Foto: unbekannt (Lizenz: CC0-Public Domain), via Maxpixel: https://www.maxpixel.net/Electronics-Pc-Motherboard-A790gxh-Chips-2202269
Im Folgenden sollen nun die Grundbausteine eines Von-Neumann Rechners näher erläutert und das Zusammenspiel der Komponenten beschrieben werden. Dabei werden moderne, technische Feinheiten keine Rolle spielen, da diese sich von Chipsatz zu Chipsatz unterscheiden. Dem Prozessor als zentrale Recheneinheit wird die größte Aufmerksamkeit geschenkt werden, da deutlich werden soll, wie es möglich ist, dass ein Gerät, das nur mit „Strom an“ und „Strom aus“ arbeitet, derartig komplexe Berechnungen durchführen kann.
Daher fangen wir ganz unten bei den Bauelementen eines Prozessors, den CMOS-Transistoren, an und bauen daraus schrittweise einen universellen, programmierbaren Computer auf.
1 Seite Jérôme Lalande. In: Wikipedia, Die freie Enzyklopädie. Bearbeitungsstand: 11. Mai 2011, 19:06 UTC.
2 Kostenloser C64-Emulator: VICE, http://www.viceteam.org (Stand: Nov. 2011)
3 Die „virtuellen Cores“, mit der die Firmen werben, sind keine echten Kerne. Hier wird der Umstand ausgenutzt, dass die Prozessor-Kerne oft nur „Däumchen drehen“, weil es nichts zu tun gibt. Dem Betriebssystem werden daher meist pro realem Kern ein virtueller Kern vorgegaukelt, um so zu erreichen, dass bei mehreren Threads nicht immer unterbrochen werden muss, um alle Threads drankommen zu lassen. Da es ja dennoch nur ein Kern ist, besteht der Geschwindigkeitsvorteil im besseren Handling der Threads.
Hintergrundinformationen: Herunterladen [odt][4 MB]
Weiter zu Schaltungen aus Transistoren