Einführung
 Diese
Seite als PDF herunterladen
[PDF] [170 KB]
Diese
Seite als PDF herunterladen
[PDF] [170 KB]
Information (Lehrer): Kleiner Führerschein für Datenbanken und ein Programm zur 3D-Visualisierung
Mit der Bioinformatik hat sich ein eigener interdisziplinärer Wissenschaftszweig entwickelt, der Sequenzdaten für Nukleinsäuren und Proteine von Organismen sammelt und organisiert, 3D-Strukturdaten verschiedenster makromolekularer Moleküle analysiert und Visualisierungsprogramme für Biomoleküle und biologische Prozesse bereitstellt. Mittlerweile wurden weltweit Abermillionen solcher Datensätze generiert. Um diese Datenflut zu verwalten und auch allen Mitgliedern (vor allem) der Wissenschaftsgemeinschaft zugänglich zu machen, existieren Datenbanken; die umfangreichste befindet sich an den National Institutes of Health (NIH) in den USA (http://www.ncbi.nlm.nih.gov/sites/gquery). Diese Art „GOOGLE"-Suchmaschine für Wissenschaftler findet und vergleicht nicht nur Sequenzdaten (grüne Markierungen), sondern ermöglicht mit „PubMed" auch die Suche nach Originalveröffentlichungen aus der biomedizinischen Forschung (rote Markierung).
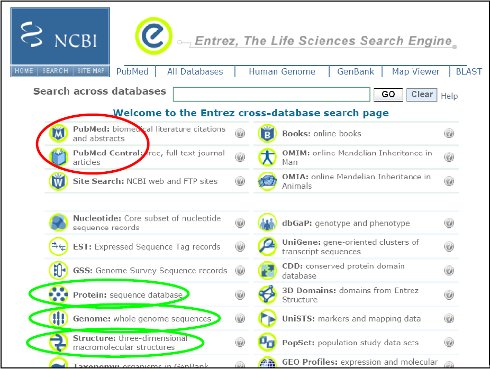
Inhalt:
(A) Kurzanleitung zur Suche von wissenschaftlichen Originalpublikationen
(B) Kurzanleitung zur Suche von Informationen über Proteine
(C) Kurzanleitung zur Nutzung des Visualisierungsprogramms PyMOL