Ausgewählte Graphen-Algorithmen
Zyklensuche
Um Zyklen in Graphen zu finden, kann man Tiefen- oder Breitensuche verwenden. Enthält der Graph keinen Zyklus, ist es ein Baum.
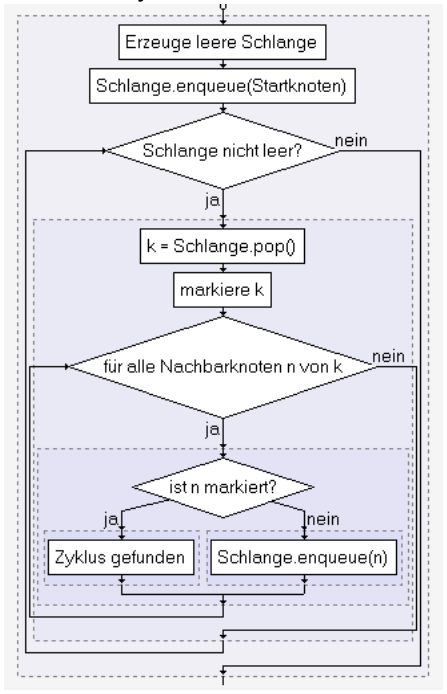
Abbildung 12: Zyklensuche durch Breitensuche
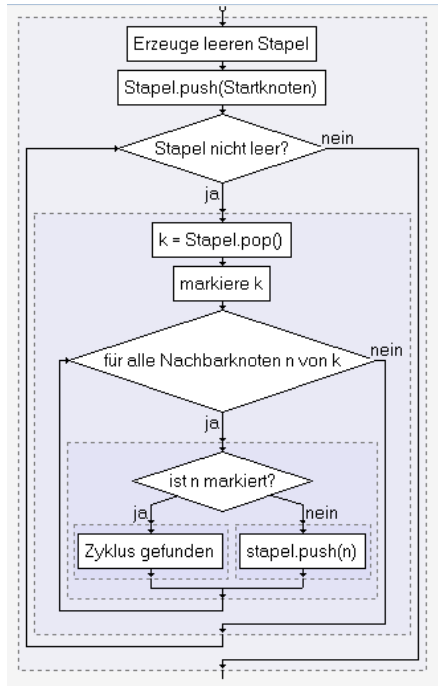
Abbildung 13: Zyklensuche durch Tiefensuche
ZPG Informatik [CC BY-SA 4.0 DE], aus 1_graphen_hintergrund.odt
Alternativ kann man auch eine rekursive Implementierung wählen.
Zusammenhang eines Graphen:
Mit Tiefen- oder Breitensuche lässt sich die Anzahl der erreichbaren Knoten in einem Graphen bestimmen und durch Vergleich mit der Gesamtzahl der Knoten erkennen, ob ein Graph zusammenhängend ist.
Euler-Zug
Gesucht ist ein geschlossener Kantenzug im Graphen, so dass jede Kante genau einmal benutzt wird. Fälschlicherweise wird der Euler-Zug oft als Euler-Kreis bezeichnet. Allerdings darf in einem Kreis laut Definition jeder Knoten nur einmal besucht werden. Beim "Euler-Kreis" allerdings mehrfach. Damit muss man ihn als korrekterweise als geschlossenen Euler-Zug oder Euler-Zyklus bezeichnen.
Dies ist möglich, wenn der Graph zusammenhängend ist und der Grad jedes Knoten gerade ist. Damit ist die Existenz nachgewiesen, aber noch nicht klar, wie der Kantenzug gefunden werden kann. Die Algorithmen von Hierholzer oder Fleury lösen dieses Problem. Da dies aber nicht im Bildungsplan vorkommt, wird hier nur auf zwei Videos verwiesen.
- Der Algorithmus von Hierholzer (Eulerzugproblem)https://www.youtube.com/watch?v=aAKDDW4gUGs (Sep. 2020)
- Der Algorithmus von Fleury (Eulerzugproblem)https://www.youtube.com/watch?v=I_6ODtkaDwo
Anwendung Briefträgerproblem:
Im Gegensatz zum Handlungsreisenden, der jede Stadt (Knoten) einmal besuchen soll, muss der Briefträger jede Straße einmal ablaufen, um die Briefe auszuliefern. Dabei sollte jede Straße nur einmal benutzt werden. Das gilt genauso für Routen der Müllabfuhr oder Straßenreinigung.
Wegefinde-Algorithmen
Moores-Algorithmus A
Finden kürzester Wege in ungewichteten Graphen: Mit dem Algorithmus A von Edward Moore wird per Breitensuche die Entfernung eines Knoten zu allen anderen bestimmt, indem man ausgehende vom Startknoten (Entfernung 0) bei jedem noch nicht besuchten Nachbarknoten als Entfernung die eigene Entfernung+1 einträgt. Die neu besuchten Knoten werden in die ToDo- Liste der Breitensuche eingetragen.
Dijkstra - Algorithmus
Der Dijkstra-Algorithmus wurde schon in IMP in Klasse 9 (siehe Hintergrund dort) erläutert. Eine gut verständliche Erläuterung finden Sie auch unter https://www-m9.ma.tum.de/graph-algorithms/spp-dijkstra/index_de.html (Abgerufen 04.11.2020).
Bellman-Ford - Algorithmus
Der Bellman-Ford-Algorithmus geht ähnlich vor wie der Dijkstra Algorithmus. Er ist unter https://www-m9.ma.tum.de/graph-algorithms/spp-bellman-ford/index_de.html (Abgerufen: Nov. 2020) gut erklärt. Wenn vom Startknoten zu einem Knoten A ein Pfad gefunden wurde, wird bei jedem Nachbarknoten N kontrolliert, ob der Weg über A zu N kürzer ist als der bisher kürzeste Weg zu N. Im Gegensatz zum Dijkstra-Algorithmus versucht man dabei nicht, die Bearbeitungs- reihenfolge der Knoten so zu wählen, dass ein schon bearbeiteter Knoten nicht erneut untersucht werden muss. Stattdessen werden so viele Bearbeitungsdurchgänge durchgeführt, dass nachträgliche Änderungen an einem Knoten erneut an alle Folgeknoten weitergegeben werden können. In einem Durchgang wird dabei jede Kante einmal betrachtet. Daher verwendet man eine Schleife über alle Kanten statt einer Schleife über alle Knoten.
Wählt man als Anzahl der Durchgänge die Knotenzahl des Graphen, stellt man sicher, dass der kürzeste Weg zu jedem Knoten gefunden wurde. Im ungünstigsten Fall verläuft der längste kürzeste Weg zu einem Knoten über alle anderen Knoten. Mehr Zwischenschritte sind nicht
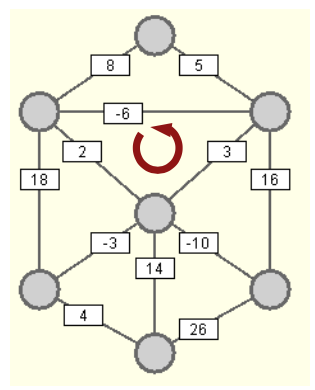
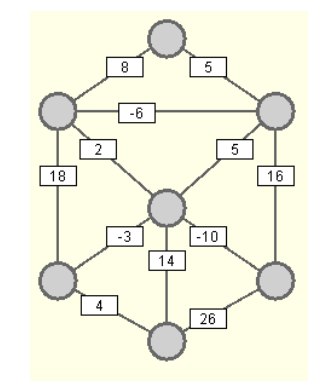
Graphen mit negativen Kantengewichten: Der erste Graph ist nicht zulässig, da der rot markierte Kreis das Gewicht -1 hat. (eigenes Werk)
ZPG Informatik [CC BY-SA 4.0 DE], aus 1_graphen_hintergrund.odt
möglich, da es im Normalfall nicht sinnvoll ist, einen Zyklus (mehrfach) zu durchlaufen. Nur bei Zyklen, die ein negatives Kantengewicht haben, würde sich die Gesamtstrecke durch den Zyklus verkürzen. Es würde sich lohnen, den Zyklus immer wieder zu durchlaufen. Daher erkennt man diese (verbotenen) Zyklen daran, dass ein weiterer Durchgang nach Beendigung des Algorithmus eine weitere Verbesserung der Wege bringen würde. Einzelne Kanten mit negativen Kantengewichten sind bei Bellman-Ford erlaubt.
Distanz-Vektor-Verfahren (Dynamisches Routing)
Die Laufzeit des Bellman-Ford-Algorithmus ist schlechter als die des Dijkstra-Algorithmus. Seine große Stärke liegt aber darin, dass er auch funktioniert, wenn man jeden Knoten als eigenständigen Akteur betrachtet, der mit seinen Nachbarknoten kommunizieren kann. Er fragt seine Nachbarn immer wieder nach deren Entfernung zu Startknoten und passt seine eigene Entfernung gegebenenfalls an. Machen das alle Knoten, stellt sich nach einer gewissen Zeit ein stabiler Zustand ein, in dem die kürzesten Entfernungen vom bzw. zum Startknoten bekannt sind. Die Gesamtstruktur des Graphen muss dazu nicht bekannt sein. Jeder Knoten muss nur seine Nachbarknoten kennen.
Statt nur die Entfernung zu einem (Start)knoten abzufragen, kann man auch die Entfernungen zu allen Knoten abfragen. Das Routing im Internet funktioniert nach diesem System. Hier tauschen die Router Informationen über den Zeitbedarf zu den Ziel-IP-Adressen aus und bestimmen damit die günstigsten Routing-Strecken.
Jeder Rechner/Router (Knoten des Graphen) kennt zunächst nur die Distanz zu seinen unmittelbaren Nachbarn. Die Distanz (Gewicht der Kante) ist ein bestimmtes Maß (=Metrik):
- die Paketverzögerung beim Transport (beim Protokoll Hello)
- die Anzahl der Hops (beim Protokoll RIP – Routing Information Protocol). Die Anzahl Hops gibt an, wie viele Router sich zwischen Ursprungs- und Zielrechner befinden.
Wir wählen bei unseren weiteren Überlegungen die Verzögerung als Maß für die Distanz. Jeder Router misst nun regelmäßig die Zeit, die ein Paket braucht, um zu seinen Nachbarn und zurück zu gelangen. Diese Zeiten hält er in einer Routingtabelle fest.
In regelmäßigen Abständen tauschen die Nachbarn ihre Routingtabellen aus (im ARPAnet waren es 625ms), in denen steht, in welcher Zeit irgendein Ziel erreicht werden kann. Aus den erhaltenen Tabellen wird eine neue Routingtabelle mit weiteren Zielen und angepassten Werten für den Zeitbedarf berechnet.
| Ziel | Netzmaske | Gateway | Schnittstelle | Metrik |
| 92.221.2.14 | 255.255.255.255 | 127.0.0.1 | 127.0.0.1 | 0ms |
| 10.1.1.17 | 255.255.255.255 | 127.0.0.1 | 127.0.0.1 | 0ms |
| 92.221.2.0 | 255.255.255.0 | 92.221.2.14 | 92.221.2.14 | 1ms |
| 10.1.0.0 | 255.255.0.0 | 10.1.1.17 | 10.1.1.17 | 1ms |
| 0.0.0.0 | 0.0.0.0 | 10.1.1.18 | 10.1.1.17 | 3ms |
Diese Tabelle ist so zu lesen, dass die Datenpakete an die Adressen 92.221.2.14 und 10.1.1.17 – also die eigenen IP-Adressen – an sich selbst weitergeleitet werden müssen. Die IP-Adresse 127.0.0.1 kennzeichnet grundsätzlich den eigenen Rechner (localhost). Die Datenpakete an alle IP-Adressen, die die Netz-ID 92.221.2.0 und Netzmaske 255.255.255.0 haben, werden über die Schnittstelle 92.221.2.14 in das Netz 92.221.2.x weitergeleitet. Entsprechendes gilt für Netz 10.1.x.x. Alle anderen Verbindungen (Ziel 0.0.0.0 / Subnet 0.0.0.0) würden an den nächsten Router mit der IP 10.1.1.18 über die Schnittstelle 10.1.1.17 weitergegeben.
Betrachten wir den Ablauf des Routingalgorithmus in einem kleinen Netzwerk mit den Routern A, B, C und D. Wenn die Router eingeschaltet werden, so kennen sie nur die Distanz zu ihren Nachbarn. Die Routingtabelle hätte die folgende Form:

ZPG Informatik [CC BY-SA 4.0 DE], aus 01_hintergrund.pdf, bearbeitet
Im Folgenden ist dargestellt, wie Informationen der Nachbarn die Routingtabelle von A verändern. Dazu schicken die Nachbarn von A Informationen über ihre Routingtabellen (= Distanzvektor).
Router B liefert z.B. (A = 2; B = 0; C = 1). A addiert die Distanz zum Router B (Entfernung A-B ist hier 2) hinzu und erhält damit die Gesamtentfernung um die anderen Knoten zu erreichen, wenn der Router B benutzt würde. Die Entfernung von A nach C über B ist also beispielsweise die Summe aus der Entfernung A-B (=2) plus die Entfernung von B zu C (=1), also insgesamt 3.
Am Ende wählt der Router A denjenigen Weg, der die kürzeste Distanz zum Ziel liefert. In diesem Beispiel ist der direkte Weg von A nach C 4 Einheiten weit weg. Über Router B sind es 3 Einheiten. Daher wird der Routingtabelleneintrag für Ziel C geändert. Statt des direkten Weges (4/C) wird der kürzere „Umweg“ über B verwendet (3/B). Für die anderen Ziele werden entsprechend die kürzesten Wege bestimmt. Man erhält eine neue Routingtabelle.
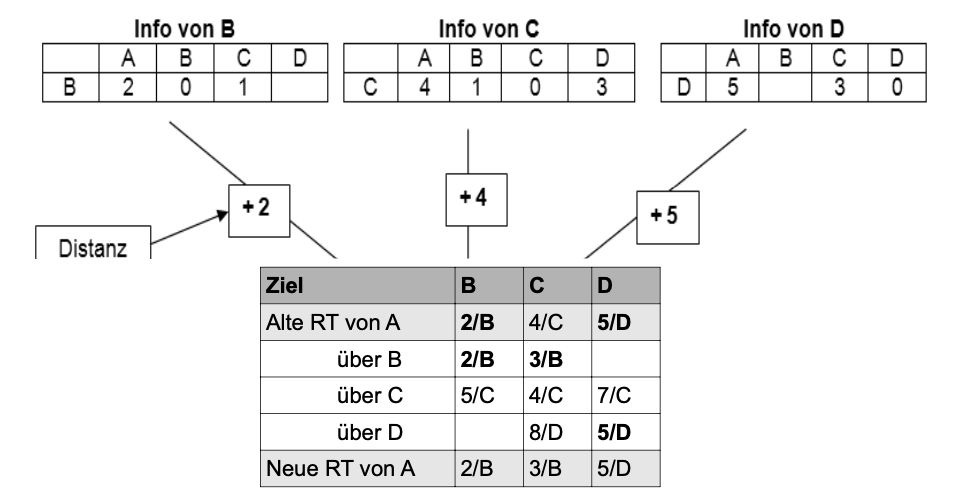
ZPG Informatik [CC BY-SA 4.0 DE], aus 01_hintergrund.pdf, bearbeitet
Werden die Routingtabellen immer wieder an die Nachbarn übertragen, so stellt sich nach einiger Zeit ein „stabiler Zustand“ ein, d.h. die Routingtabellen ändern sich nicht mehr. Hiermit ist das Grundprinzip des Bellman-Ford-Algorithmus umgesetzt.
In der Praxis ist das Verfahren ein wenig komplizierter, da bei diesem Verfahren erst nach mehrfachem Austausch der Tabellen ein stabiler Zustand im Netz erreicht wird. Dazwischen kann es auch passieren, dass eine Routingschleife entsteht. Diese führt dazu, dass Datenpakete immer im Kreis geschickt werden und diese Leitungen dann schnell verstopfen. Um dies zu verhindern, hat man eine Time To Live (TTL) eingeführt, die festlegt, nach wie vielen Hops das Paket gelöscht wird. So kreist ein Paket nicht für immer und ewig.
In modernen Routing-Protokollen (BGP – Border Gateway Protocol) werden solche Routingschleifen von vornherein verhindert. Trotzdem arbeitet das BGP im Prinzip nach dem Distanz-Vektor-Verfahren. Es gibt aber auch andere Routingalgorithmen, die wie bei einem Routenplaner, die Entfernung zu allen Zielen z.B. mit dem Dijkstra-Algorithmus selbstständig berechnen (Link-State-Verfahren).
Unverträglichkeitsgraphen: Kolorierung von Graphen
Deutschlandkarte_(Bunt).svg: Stefan-Xp [CC BY-SA 3.0], via Wikimedia Commons
Abbildung 14: Bundesländer in Deutschland
Landkarten werden normalerweise koloriert, um einzelne Gebiete gut unterscheiden zu können. Dabei dürfen benachbarte Gebiete nicht in derselben Farbe gefärbt werden. Die Gebiete können als Knoten eines ungerichteten, ungewichteten Graphen mo- delliert werden, eine Kante zwischen zwei Knoten zeigt, dass die Regionen eine gemeinsame Grenze haben. Die genaue Lage der Gebiete und der Verlauf der Grenzen spielt keine Rolle.
Der Graph ist damit ein Unverträglichkeits- graph. Eine Kante drückt aus, dass die gleiche Farbe für die Knoten verboten ist.
Das Kartenfärbeproblem und damit auch alle anderen Anwendungssituationen, die mit einem Unverträglichkeitsgraph dargestellt werden können, können daher folgendermaßen in ein Graphen-Färbeproblem umformuliert werden:
Graph Coloring Problem
Finde eine Färbung der Knoten eines Graphen mit möglichst wenigen Farben, so dass benachbarte Knoten nicht die gleiche Farbe haben.
Als Variante kann man auch entweder nur danach fragen, wie viele Farben benötigt werden oder ob es zu einer bestimmten Anzahl von Farben eine Färbung gibt.
Für Graphen von Landkarten ist bekannt, dass immer eine Färbung mit maximal vier Farben möglich ist. Dies liegt daran, dass der dazugehörige Graph auf jeden Fall planar ist.
Eine Variante des Problems der Kartenkolorierung stellt die Erweiterung um Kolonien dar: Mutterstaat und Kolonie sollen dieselbe Farbe haben. Die Kolonien und der dazugehörige Mutterstaat werden dabei als ein einziger Knoten modelliert, um sicherzustellen, dass sie die gleiche Farbe bekommen. Die Kanten behalten ihre Bedeutung. Der dazugehörige Graph ist im Allgemeinen nicht mehr planar. Für dieses Problem ist keine allgemein gültige obere Schranke für die minimale Anzahl der Farben bekannt.
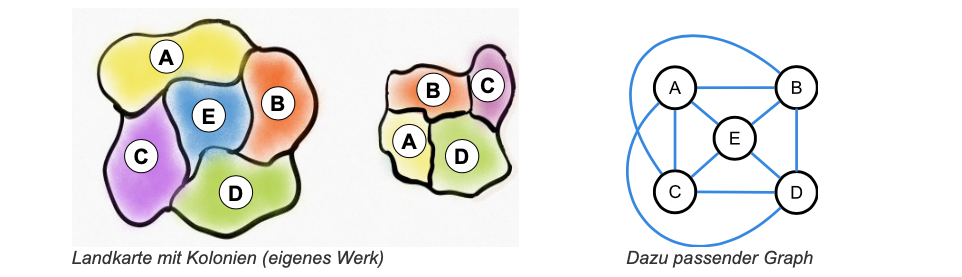
ZPG Informatik [CC BY-SA 4.0 DE], aus 01_hintergrund.pdf, bearbeitet
Graphen, die sich mit einer Farbe färben lassen, haben keine Kante. Ein bipartiter Graph lässt sich mit zwei Farben färben. Ein vollständiger Graph mit n Knoten benötigt n Farben, ein Graph mit einer Clique aus m Knoten mindestens m Farben.
Algorithmen
Das Graph-Kolorierungsproblem ist im Allgemeinen ein NP-vollständiges Problem. Daher kann man es vermutlich nicht effizient optimal lösen. Backtracking würde eine optimale Lösung garantieren. Die Anzahl der Farben würde man bei n Knoten auf n festlegen, da dies auf jeden Fall ausreicht. Dann würden die Knoten rekursiv abgearbeitet und für jeden Knoten alle Farben probiert. Die beste Lösung merkt man sich.
Als effizientes Näherungsverfahren steht ein Greedy-Algorithmus zur Verfügung. Schrittweise werden die Knoten einer nach dem anderen betrachtet und jeweils der Knoten so mit einer Farbe der höchsten Priorität (diese wurde zuvor festgelegt) gefärbt, dass die Färbe-Regel nicht verletzt wird.
Graph-Coloring-Approximationsalgorithmus (Greedy):
- Lege eine Farb-Prioritätsliste fest: 1. Farbe, 2. Farbe, 3. Farbe, …
- Betrachte der Reihenfolge nach alle n Knoten → u sei der betrachtete Knoten:
Die Güte dieses Algorithmus ist sehr schlecht. Beim einem bipartiten Graph, bei dem jeder Knoten mit allen Knoten der anderen Teilmenge verbunden ist außer seinem direkten Gegenüber, benötigt der Algorithmus n/2 Farben, wenn man die Knoten in ungünstiger Reihenfolge (siehe Nummerierung der Knoten) abarbeitet, obwohl eigentlich 2 Farben ausreichen17 .
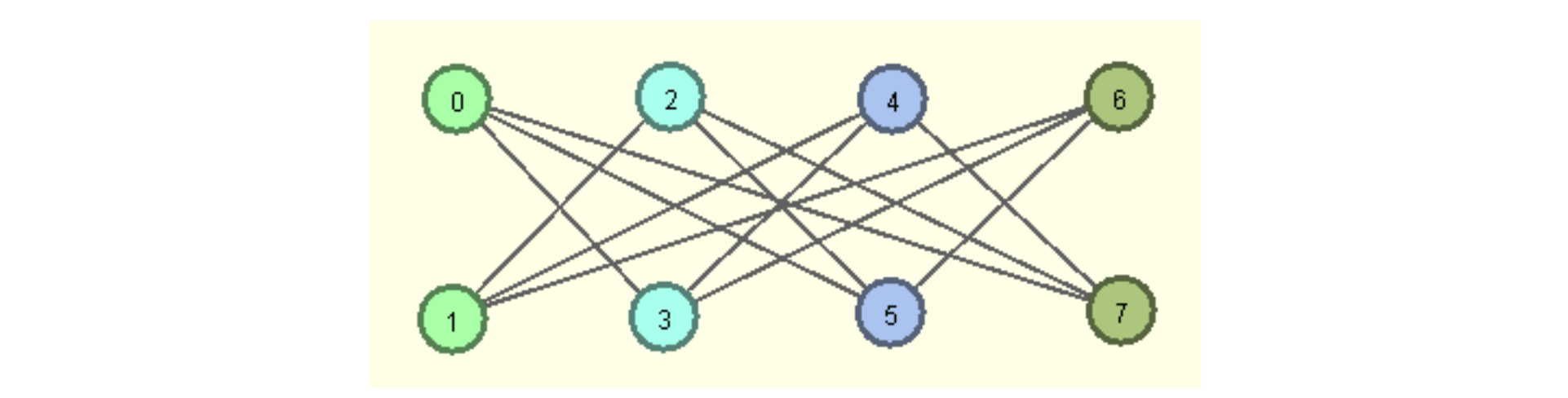
Die Bearbeitungsreihenfolge (0->7) führt dazu, dass die gegenüberliegenden Knoten immer in der gleichen Farbe gefärbt werden und diese Farbe für alle anderen Knoten verboten ist. ZPG Informatik [CC BY-SA 4.0 DE], aus 01_hintergrund.pdf, bearbeitet
Quellen
Erklärvideo zur GraphColoring https://www.youtube.com/watch?v=4FE79y_JkCE
Erklärvideo Four Color Problem: https://www.youtube.com/watch?v=9-ImSBdxx3k
Erklärvideo The Four Color Theorem: https://www.youtube.com/watch?v=NgbK43jB4rQ
Wikipedia: Färbung https://de.wikipedia.org/wiki/Färbung_(Graphentheorie)
CSUnplugged: Graph Colouring – The Poor Cartographer. URL: http://csunplugged.org/graph-colouring/
Großer et al: Das Vierfarbenproblem – "mehr als Malen nach Zahlen". MathePrisma. URL: http://matheprisma.de/Module/4FP/index.htm
Computing Science Inside: Graph Coloring. University of Glasgow. URL: http://csi.dcs.gla.ac.uk/workshop-view.php?workshopID=6
Minimale Dominierende Menge (Minimal Dominating Set - MDS)
In der Graphentheorie ist eine Dominierende Menge eines Graphen eine Teilmenge, für die gilt, dass jeder Knoten, der nicht in D enthalten ist, adjazent zu mindestens einem Knoten aus D ist.
Die Dominationszahl ist die Anzahl Knoten in einer minimalen Dominierenden Menge für G.
Das Dominating Set Problem betrifft die Frage, ob die Dominationszahl für einen gegebenen Graphen G und höchstens k ist, wobei k in der Problemstellung festgelegt wird. Dies ist ein überraschend schweres Problem. Es ist ein klassisches NP-vollständiges Entscheidungsproblem in der Komplexitätstheorie (Garey & Johnson 1979). Daher kann man davon ausgehen, dass es keinen effizienten Algorithmus gibt, der eine Minimale Dominierende Menge für einen vorgegebenen Graphen findet.
[Übersetzt aus Wikipedia: https://en.wikipedia.org/wiki/Dominating_set ]
Algorithmus
Auch hier bietet es sich an, für eine optimale Lösung mit Backtracking an das Problem heranzugehen. Jeder Knoten kann zur dominierenden Menge dazugehören oder nicht. Damit gibt es zwei Möglichkeiten, die beim Backtracking getestet werden müssen. Die kleinste gefundene dominierende Menge wird gespeichert.
Greedy-Näherungslösung: Man untersucht alle bisher noch nicht überdeckten Knoten und bestimmt die Anzahl der Knoten, die von dem jeweiligen Knoten überdeckt würden. Dann wählt man denjenigen Knoten aus, der die meisten Knoten überdeckt. In der Praxis ist es sinnvoll zu markieren, welche Knoten schon überdeckt sind, damit nicht jedes Mal alle Nachbarn darauf getestet werden müssen, ob sie zur dominierenden Menge gehören.
Lokale Suche: Man wählt zunächst zufällig so lange neue Knoten aus und fügt sie der dominierenden Menge hinzu, bis alle Knoten überdeckt sind. Danach überprüft man, ob es Knoten gibt, die aus der dominierenden Menge entfernt werden können.
Genetisch: Man generiert Individuen zunächst als zufällige Teilmengen der Knotenmenge. Dabei müssen diese nicht notwendigerweise dominierende Mengen sein. Man könnte diese Teilmenge aber leicht zu einer dominierenden Menge erweitern, indem alle restlichen Knoten, die noch nicht von der Teilmenge überdeckt werden, hinzugefügt werden. Dadurch bekommt man auf jeden Fall eine dominierende Menge.
Wenn man die Anzahl der Knoten in der dominierenden Menge minimieren will, ist das gleichbedeutend damit, dass man die Anzahl der überdeckten Knoten maximieren möchte. Daher kann man die Anzahl der überdeckten Knoten als Bewertung eines Individuums benutzen. Für die Rekombination wählt man eine beliebige Knotennummer m aus. Das neu generierte Individuum enthält dann alle Knoten, die in der Teilmenge des Vaters enthalten waren und eine Nummer kleiner m haben, und alle Knoten, die in der Teilmenge der Mutter enthalten waren und eine Nummer größer gleich m haben. Anschließend wählt man einige Indizes aus und fügt den Knoten hinzu, wenn er bisher nicht in der Teilmenge enthalten war oder entfernt ihn, wenn er enthalten war18 .
Links
Wikipedia: Minimal Dominating Set https://en.wikipedia.org/wiki/Dominating_set
CS Unplugged: Dominating Sets – Tourist Town. http://csunplugged.org/dominating-sets/
Asymmetrische Verschlüsselung mit exakten dominierenden Mengen
Graphen mit einer exakten dominierenden Menge könnten theoretisch als Public Key für asymmetrische Verschlüsselungen eingesetzt werden und schlagen damit eine Brücke zum Teilgebiet der Kryptologie. Im Bildungsplan taucht diese Verbindung aber nicht auf und ist hier nur als Hintergrund für den Lehrer gedacht.
Eine exakte dominierende Menge ist eine Menge von Knoten, die den Graphen genau überdeckt. Kein Knoten ist also Nachbar von zwei Knoten der dominierenden Menge. Dabei ist der Graph der öffentliche Schlüssel und die exakte dominierende Menge das Geheimnis, also der private Schlüssel. Es ist nur mit großem Aufwand (exponentielle Laufzeit) möglich, aus dem öffentlichen Schlüssel das Geheimnis zu berechnen. Dies ist typisch für die asymmetrische Verschlüsselung, bei der die Sicherheit nicht darauf beruht, dass es unmöglich ist, die Verschlüsselung zu brechen, sondern lediglich der Zeitaufwand zu groß ist.
Möchte man nun eine Nachricht (eine Zahl) verschlüsseln, muss man sie zufällig in einzelne Summanden aufteilen und an jeden Knoten einen dieser Summanden schreiben. Dann addiert man bei jedem Knoten K die Zahl selbst plus alle Zahlen der Nachbarknoten und trägt das Ergebnis beim Knoten K ein. Dies stellt dann die verschlüsselte Nachricht dar.
Beispiel:
unverschlüsselte Nachricht: 70
Aufteilung auf 8 Summanden: 70 = 10 + 5 + 7 + 9 + (-6) + 20 + 9 + 16
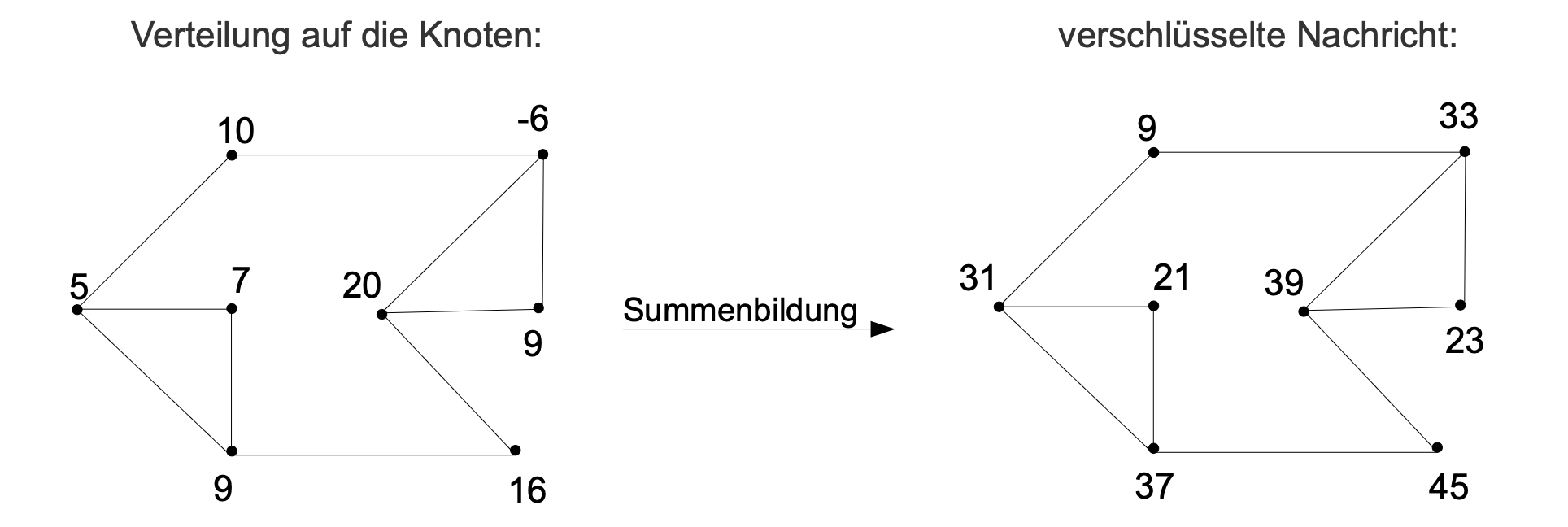
Bildquelle: Programmierparadigmen von ZPG Informatik [CC BY-SA 4.0 DE], aus 01_hintergrund.pdf, bearbeitet
Kennt man das Geheimnis des Graphen, also die exakte überdeckende Menge, muss man lediglich die Zahlen an diesen Knoten in der verschlüsselten Nachricht ablesen und addieren, um die Nachricht zu entschlüsseln (31+39 = 70), da an diesen Knoten die Summe aller anderen Knoten eingetragen und kein Knoten doppelt berücksichtigt wurde.
Man kann die verschlüsselte Nachricht auch angreifen, indem man ein lineares Gleichungssystem mit n Unbekannten und n Gleichungen (bei einem Graphen mit n Knoten) aufstellt, um aus der verschlüsselten Nachricht wieder die verteilten Zahlen zu ermitteln.
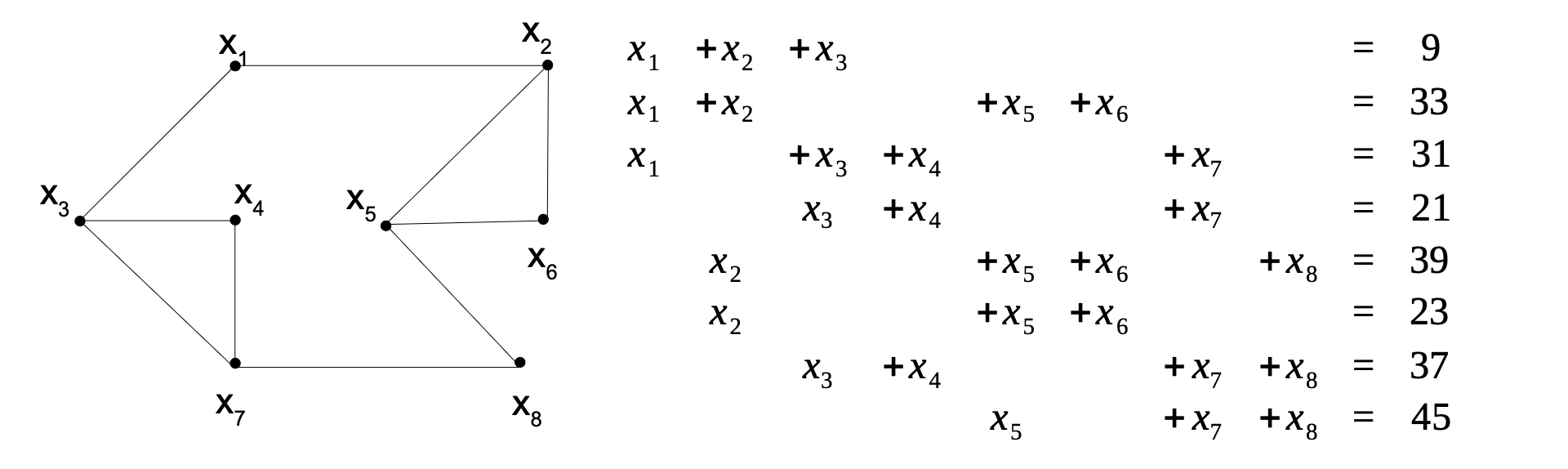
Bildquelle: Programmierparadigmen von ZPG Informatik [CC BY-SA 4.0 DE], aus 01_hintergrund.pdf, bearbeitet
Dieses Gleichungssystem lässt sich nach dem Gaußverfahren in O(n3) lösen. Damit ist dieser Angriff effektiver als das Ermitteln der überdeckenden Menge. Die normale Entschlüsselung ist aber in O(n) durchführbar. Damit kann durch eine ausreichend große Zahl von Knoten eine hohe Sicherheit erreicht werden. Der Aufwand ist im Vergleich zum üblichen RSA Verfahren aber zu groß. Das Verfahren veranschaulicht aber das Prinzip der asymmetrischen Verschlüsselung gut.
Einen geeigneten Graphen erzeugt man, indem man zunächst die Knoten der exakt dominierenden Menge zeichnet. Dann verteilt man eine beliebige Zahl von weiteren Knoten und verbindet jeden von diesen mit genau einem der dominierenden Menge. Danach können beliebig viele Kanten zwischen diesen weiteren Knoten einfügen (aber nicht mehr zu einem Knoten der dominierenden Menge).
Links
Präsentation Public Key Kryptologie, Dr. Lucia Di Caro (ETH Zürich) am Schweizer Tag der Informatik 2020, URL:https://www.abz.inf.ethz.ch/wp-content/uploads/2020/03/Workshop_16_PublicKeyKryptologie.pdf
Minimaler Spannbaum (Minimal Spanning Tree – MST)
Man sucht in einem gewichteten Graphen mit positiven Gewichten diejenigen Kanten, die alle Knoten verbinden und deren Gesamtgewicht möglichst klein ist. Es ist klar, dass Zyklen nicht auftreten können, da man dann eine Kante weglassen könnte und eine bessere Lösung hätte. Daher ist die Lösung auf jeden Fall ein Baum. Enthält der Baum alle Knoten des ursprünglichen Graphen nennt man ihn Spannbaum. Gesucht ist also ein minimaler Spannbaum.
Minimal spannende Bäume:
Jeder minimale Spannbaum ist ein zusammenhängender und zyklenfreier Graph mit minimalem Kantengewicht.
Minimale Spannbäume sind nicht nur für Gas- und Stromnetze nützlich, sie helfen auch, Probleme in Rechnernetzen, Telefonnetzen, Pipelines, Flugrouten und beim Entwurf von Computerchips zu lösen. Allgemein kann man sagen, dass Minimale Spannbäume immer dann interessant sind, wenn das Errichten der Routen teuer, das Verwenden der Routen aber billig ist. Allerdings müssen bei der Routenplanung immer verschiedene, häufig sich widersprechende Interessen berücksichtigt werden – zum Beispiel der Komfort einer Route, die benötigte Zeit und die Kosten. Daher ist der MST-Algorithmus keine große Hilfe bei der Routenplanung, da es ausschließlich ein Kriterium minimiert: die Gesamtlänge aller Straßen oder Flugstrecken. Trotzdem erkennt man bei der Berechnung eines MST für die größten deutschen Städte einen Teil des real existierenden Autobahnnetzes.
Minimale Spannbäume sind auch nützlich als ein Schritt auf dem Weg zur Lösung anderer (schwierigerer) Probleme auf Graphen, wie zum Beispiel das „Problem des Handlungsreisenden“ (Traveling Salesman Problem, TSP).
Obwohl das Problem nicht so einfach zu sein scheint, ist es nicht NP-vollständig. Es gibt effiziente Algorithmen, um einen minimale Spannbaum in polynomieller Zeit zu finden.
Algorithmen
Hier werden die Grundprinzipien zweier verschiedener Algorithmen zur Lösung des MST-Problems skizziert:
Der Prim-Algorithmus:
Dieser Algorithmus liefert garantiert einen MST.
Idee: Man betrachtet einen Teilbaum (zu Beginn einen beliebigen Knoten) und bestimmt die kürzeste Kante von diesem Baum zum restlichen Graphen. Diese Kante (zusammen mit dem Endknoten) fügt man dem MST hinzu. Dies wiederholt man bis alle Knoten im MST enthalten sind. Es ergibt sich folgender Algorithmus:
- Sortiere die Liste alle Kanten nach ihrem Gewicht.
- Nimm einen beliebigen Knoten k und markiere ihn.
- Suche die kürzeste Kante, die einen markierten und einen nicht markierten Knoten verbindet.
- Markiere diese Kante und ihren noch nicht markierten Endknoten.
- Wiederhole Schritte 3 und 4 bis alle Knoten markiert sind (also n-1 mal).
Der Algorithmus hat polynomielle Laufzeit, da das Sortieren der Kanten in polynomieller Laufzeit möglich ist (es gibt bei n Knoten höchsten m=n2 viele Kanten) und danach in jedem Schritt ein Knoten hinzugefügt wird. Das Suchen der kürzesten Kante, die einen nicht markierten mit einem markierten Knoten verbindet, ist in O(m) möglich.
Der Kruskal-Algorithmus
Auch dieser Algorithmus liefert garantiert einen MST.
Idee: Die Kanten mit den kleinsten Gewichten müssen im MST enthalten sein, wenn dadurch nicht ein Zyklus entsteht. Daher kann man die Kanten nach aufsteigenden Gewichten durchlaufen und kontrollieren, ob durch Hinzunahme zum Teilgraph der Kante ein Zyklus entsteht. Der Teilgraph ist zunächst (meist) ein Wald und wird allmählich zu einem Baum ergänzt.
Um sich die aufwändige Zyklensuche zu ersparen, kann man auch jeden Baum des Waldes in einer Farbe färben. Dann kann man an der Knotenfarbe erkennen, zu welchem Baum ein Knoten gehört. Es ergibt sich folgender Algorithmus:
- Sortiere alle Kanten des Graphen nach aufsteigenden Gewichten.
- Betrachte nacheinander alle Kanten der Sortierung nach (beginne also mit der Kante mit dem kleinsten Gewicht)
- Sind die Endknoten im gleichen Baum (ihre Farbe ist gesetzt und gleich), dann lösche die Kante, sonst markiere sie.
- Ist die Farbe beider Knoten noch nicht gesetzt, färbe beide in einer neuen Farbe.
- Ist die Farbe eines Knoten noch nicht gesetzt, färbe ihn in der Farbe des anderen.
- Sind beide gefärbt und die Farbe unterscheidet sich, dann färbe einen der Bäume komplett in der Farbe des anderen.19
Der Algorithmus hat polynomielle Laufzeit, da das Sortieren in polynomieller Laufzeit (es gibt höchsten n2 viele Kanten) möglich ist und danach in jedem Schritt eine Kante abgearbeitet wird.
Beide Algorithmen sind Greedy-Algorithmen. Sie treffen in jedem Schritt die beste Wahl, die momentan zur Verfügung steht. Obwohl sowohl der Prim- als auch der Kruskal-Algorithmus so „kurzsichtig“ und gierig sind, ohne Rücksicht darauf zu nehmen, welche Auswirkungen die getroffene Entscheidung für den weiteren Verlauf hat, lösen beide das MST-Problem. Sie liefern nicht nur eine Näherungslösung, wie es beim Graph-Coloring-Algorithmus der Fall ist.
Beide Algorithmen lassen sich mit leichten Veränderungen auch benutzen, um eine Näherungslösung für das Traveling Salesman Problem zu suchen:
Der Prim-Algorithmus vereinfacht sich, da die kürzeste Kante von einem markierten zu einem unmarkierten Knoten für das TSP nicht im ganzen bisherigen Baum gesucht werden muss, sondern am Ende der Route liegen muss. Man muss also nur die ausgehenden Kanten des Routenendes zu allen noch nicht markierten Knoten betrachten (vgl. TSP-Greedy im Graphentester). Am Ende wird die Rundreise durch eine Kante zwischen den beiden Blättern des "Baums" geschlossen.
Der Kruskal-Algorithmus ist etwas komplizierter, da man beim Zusammenführen zweier Teilbäume oder Vergrößern eines Teilbaums darauf achten muss, dass keine innere Knoten sondern nur Blätter verwendet werden dürfen. Außerdem muss zum Schließen der Rundreise am Ende einmal erlaubt werden, einen Kreis zu bilden.
Matching-Algorithmen
Da Matching-Algorithmen im Bildungsplan nicht vorkommen, werden die Algorithmen hier nicht näher beleuchtet. Sie sind aber trotzdem spannend, da sie viele reale Probleme umfassen und quasi das Gegenstück zum Färben eines Unverträglickeitsgraphen bilden. Eine gute Darstellung des Hopcroft-Karp-Algorithmus für bipartites Matching und des Blossom-Algorithmus für beliebige Graphen findet man bei der TUM München. Dort kann man auch mit verschiedenen Graphen experimentieren.
Hopcroft-Karp-Algorithmus: https://www-m9.ma.tum.de/graph-algorithms/matchings-hopcroft-karp/index_de.html
Blossom-Algorithmus von Edmonds: https://www-m9.ma.tum.de/graph-algorithms/matchings-blossom-algorithm/index_de.htmlAbgerufen 25.11.2020
17 Greedy Coloring in Wikipedia, freie Enzyklopädie, https://en.wikipedia.org/wiki/Greedy_coloring (12.05.2020)
18 Näheres dazu: Cu Nguyen Giap und Dinh Thi Ha, https://www.researchgate.net/publication/277013536_Parallel_Genetic_Algorithm_for_Minimum_Dominating_Set_Problem
19 Dies ist der schwierige Teil des Algorithmus, wenn er effizient implementiert werden soll. Dazu verwendet man sogenannte „Disjoint-Set“-Datenstrukturen (vgl. https://en.wikipedia.org/wiki/Disjoint-set_data_structure ).
Hintergrundinformationen: Herunterladen [odt][990 KB]
Weiter zu Unterrichtsverlauf