Rekursion
Rekursive Funktionen zeichnen sich dadurch aus, dass sie sich in ihrem Verlauf selbst aufrufen können. Bei einem rekursiven Aufruf (Rekursionsschritt) wird das zu lösende Problem (d.h. die Parameter des Aufrufs) typischerweise verkleinert, bis die Problemgröße irgendwann so gering ist, dass das Problem direkt gelöst werden kann (Rekursionsbasis).
Eine rekursive Funktion, die bei einem Durchlauf höchstens einen rekursiven Aufruf ausführt, wird lineare Rekursion genannt. Sind mehrere Rekursionsaufrufe möglich, spricht man von kaskadenförmiger Rekursion.
In beiden Fällen muss der Computer sich beim Aufruf einer rekursiven Funktion20 merken, von welcher Stelle im Programmcode der Sprung ausgeführt wurde, damit es möglich ist, nach Abschluss des Unterprogramms wieder an die Ausgangsadresse zurückzuspringen. Hier gilt die Regel, dass die zuletzt verlassene Funktion zuerst wieder fortgesetzt werden muss, was einem LIFO-Prinzip entspricht. Es muss also ein Stack aufgebaut werden, der sogenannte „call stack“.
Zudem werden die lokalen Variablen und Parameter zwischengespeichert, so dass sie beim Rücksprung wiederhergestellt werden können. Diese Informationen werden in sogenannte „Stack Frames“ zusammengefasst und in einem gesonderten Bereich des Arbeitsspeichers (dem „Stack-Segment“) abgelegt. Dieser Speicher umfasst bei Java (abhängig von Betriebssystem und Prozessorarchitektur) standardmäßig zwischen 64 und 1024 KB21. Bei rekursiven Funktionen kann es passieren, dass dieser Speicher vollläuft. Dies liegt dann meist entweder an einem Programmfehler (fehlende Abbruchbedingung) oder daran, dass die übergebenen Parameter zu groß sind.
Darstellungen
Den Ablauf einer rekursiven Funktion kann man mit dem Inhalt seines Call-Stacks darstellen. Wir betrachten als Beispiel die Fibonacci-Funktion:
fib(n):
(1) erg = n
(2) falls n > 1:
(3) erg = fib(n-2)
(4) erg += fib(n-1)
(5) return erg
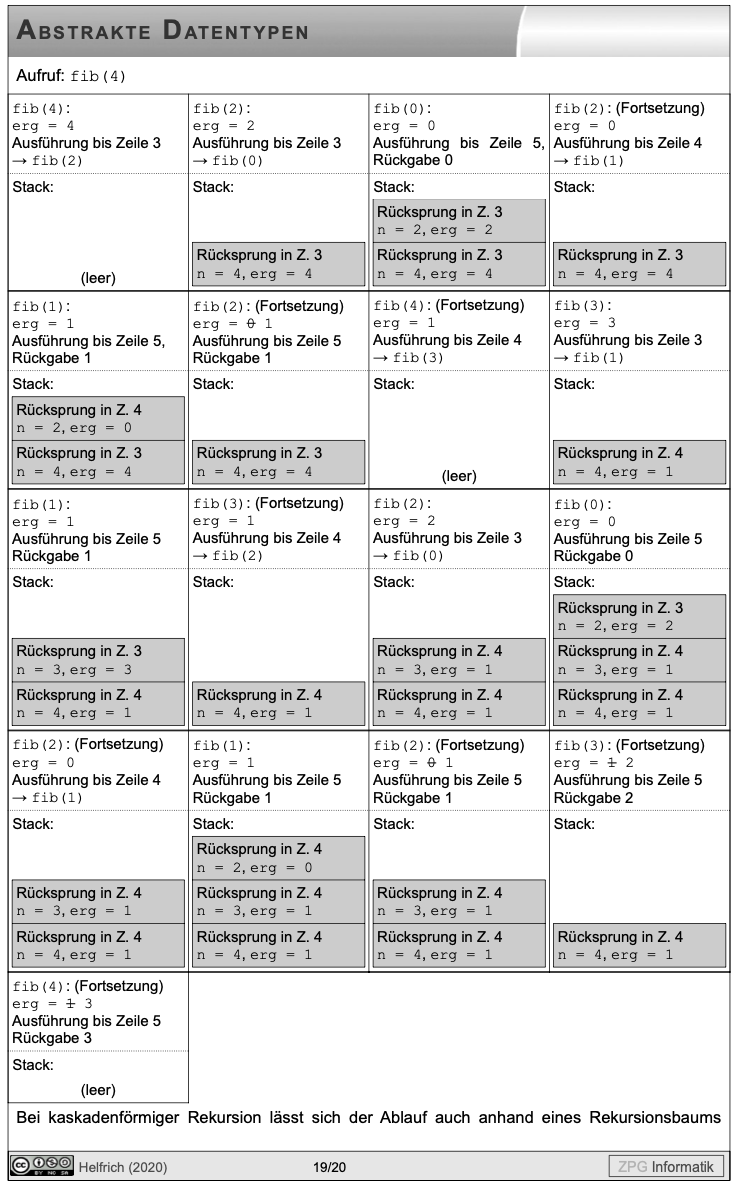
Bildquelle: Ablauf einer rekursiven Funktion von ZPG Informatik [CC BY-NC-SA 3.0 DE], aus 02_hintergrund_adts.odt
Bei kaskadenförmiger Rekursion lässt sich der Ablauf auch anhand eines Rekursionsbaums darstellen22. Hierbei steht jeder Knoten für einen Funktionsaufruf, seine Kindknoten sind die von diesem Funktionsdurchlauf ausgehenden rekursiven Aufrufe.
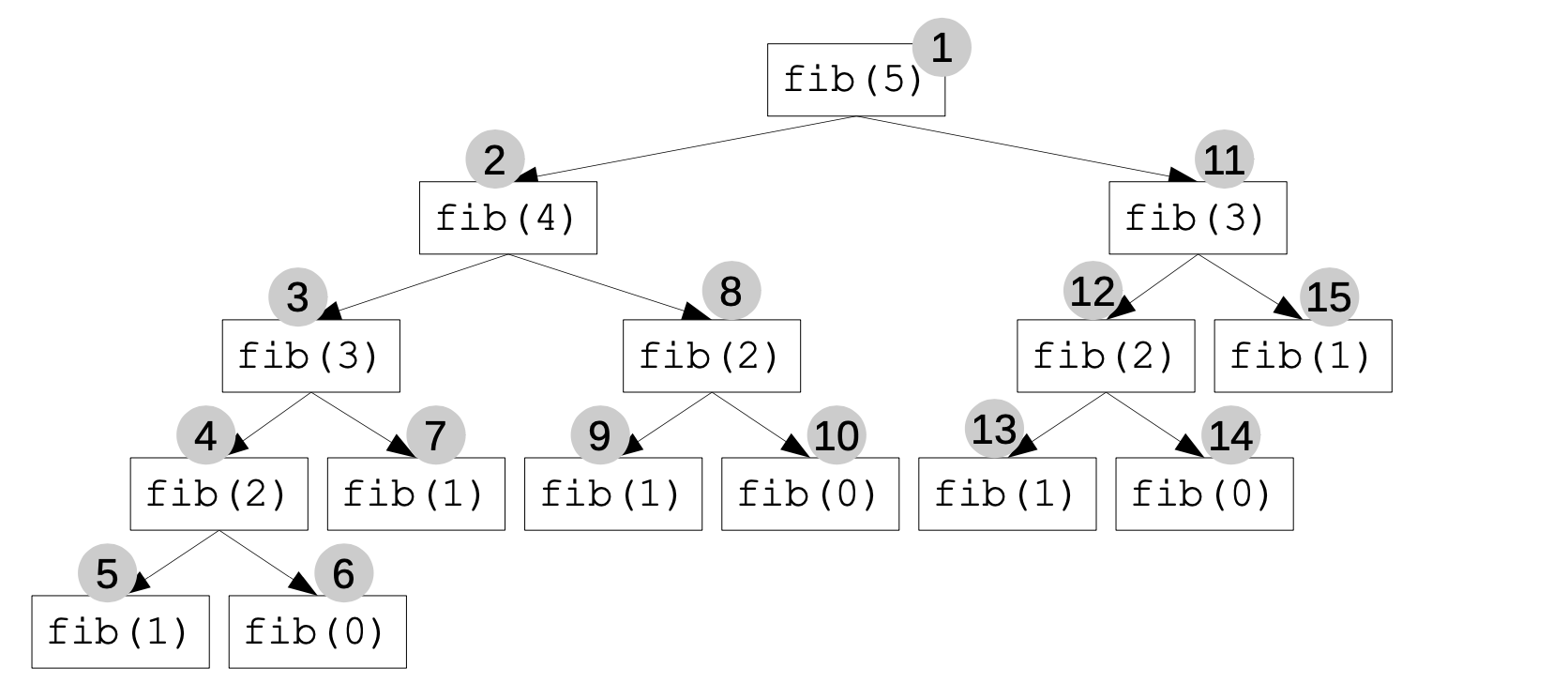
Bildquelle: Rekursionsbaum von ZPG Informatik [CC BY-NC-SA 3.0 DE], aus 02_hintergrund_adts.odt
Eine solche Darstellung kann bei größeren Eingabewerten schnell unübersichtlich werden, daher ist sie nur für kleine Eingaben oder grundsätzliche Überlegungen sinnvoll.
Der Rekursionsbaum zeigt auch sehr schön, dass die rekursive Implementation der Fibonacci-Funktion wenig effizient ist, da immer wieder die gleichen Teilbäume entstehen. Eine bessere Technik wäre entweder eine iterative Implementation oder die Verwendung von dynamischer Programmierung bzw. Memoisation23 :
cache = new int[…]
// So viele Plätze, wie der erste Aufruf von fib festlegt
fib(n):
falls cache[n] > 0:
return cache[n]
erg = n
falls n > 1:
erg = fib(n-2)
erg += fib(n-1)
cache[n] = erg
return erg
20 Genaugenommen ist dies bei jedem Unterprogramm nötig. Wenn keine Rekursion verwendet wird, können Unterprogramme prinzipiell vom Compiler „expandiert“ werden und man kommt auf Assembler-Ebene ohne Stack aus. Bei rekursiven Funktionen ist dies allerdings prinzipiell unmöglich, da die Anzahl der Funktionsaufrufe meist von den Daten abhängt.
21 Die Größe des Stacksegments kann beim Start der Java-VM manuell gesetzt werden: https://docs.oracle.com/cd/E13150_01/jrockit_jvm/jrockit/jrdocs/refman/optionX.html#wp999540
22 Die Darstellungsform ist auch für lineare Rekursionen möglich, allerdings ist der Erkenntnisgewinn relativ gering.
23 https://de.wikipedia.org/wiki/Memoisation
Hintergrundinformationen: Herunterladen [odt][305 KB]
Weiter zu Definition